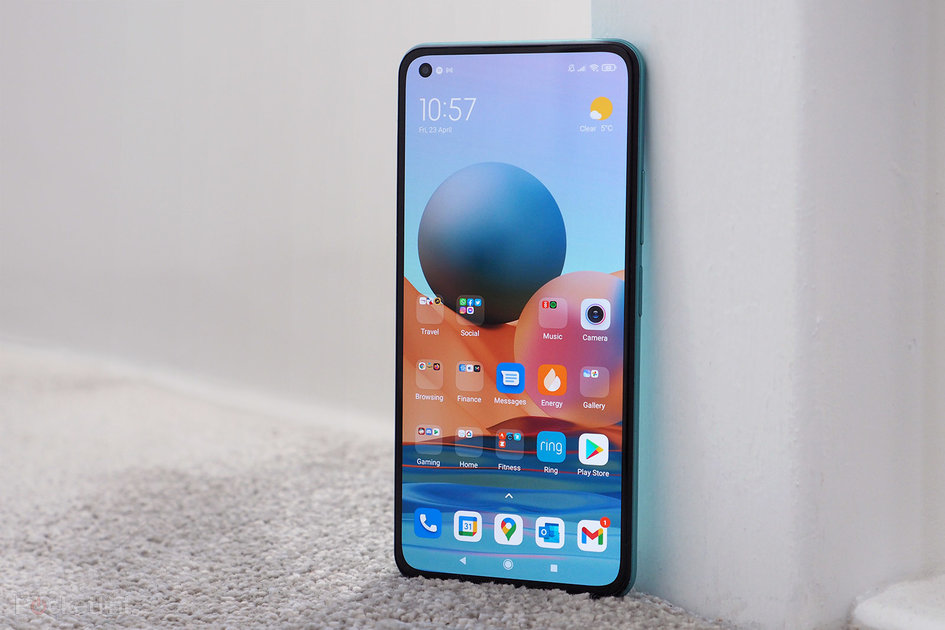
The vivo V21 trio may have the best selfie camera we’ve seen in recent years, perhaps apart from phones that can use the main cam for the job (those pricey foldables and phones with a second screen on the back). But this is a mid-ranger – actually, three mid-rangers. Meet the vivo V21, V21 5G and V21e. The first two are essentially identical besides the network connectivity, the e model switches over to a Snapdragon chipset and has some additional differences.
The V21 and V21 5G share a 44MP front-facing camera. It has OIS, which we haven’t seen for years on this side. And it also features EIS for extra smoothness in handheld videos, which can be recorded in 4K resolution.
The vivo V21 and V21 5G have dual LED flash on the front to help out the OIS-enabled selfie camera
The front camera lives inside a notch, no fancy pop-up mechanisms here. And it has two LEDs embedded in the top frame to help out after dark, plus an AI Night Portrait mode. This camera also features autofocus – something not all flagships have.
The vivo V21e also has a 44MP selfie camera with autofocus, however the OIS system is gone (there is electronic stabilization, however). The dual LED flash is also missing in action, at least the Night Portrait and Super Night Selfie modes remain.
The three models feature the exact same triple camera setup on their backs. It starts with 64MP main camera, which has OIS. The front and the rear cameras can be used for split-screen vlogs. The main camera is joined by an 8 MP ultra wide-angle camera and a 2 MP macro module.
The three V21 models аре impressively thin, one of them is vivo’s thinnest 5G phone yet. Note that the different colorways have different finishes on the back and slightly different thicknesses and weights. Either way, you’re looking at 7.29mm or 7.38mm. There’s a camera bump on the back of course, but the impressive part is that this frame fits a front camera with OIS (and, thankfully, there’s no such thing as a selfie camera bump).
Going back to the front, there is a 6.44″ AMOLED display with 90Hz refresh rate. The panel has 1080p+ resolution (20:9) and is built using the older E3 emissive material from Samsung. The V21 and V21 5G support HDR10+, the V21e model takes a step back to HDR10. The e model has a dimmer display too, with 430 nits typical brightness, compared to 500 nits for the other two. All three have a fingerprint reader built into the display.
6.44″ AMOLED displays on both, with some differences: vivo V21 and V21 5G • vivo V21e
Both the vivo V21 and V21 5G are powered by the same chipset, the Dimensity 800U, a 7nm chip with two Cortex-A76 cores (2.4GHz) plus six A55 cores (2.0GHz) and a Mali-G57 MC3 GPU. On the 5G model, it will deliver (theoretical) peak download speeds of up to 2.3 Gbps, the 4G model will, of course, be slower.
vivo V21 and V21 5G are powered by a Dimensity 800U • The vivo V21e gets a Snapdragon 720G instead
The vivo V21e switches things around and comes equipped with a Snapdragon 720G chipset – an 8 nm chip with two Cortex-A76 derived cores (2.3GHz) and six A55 derived cores (1.8GHz), plus an Adreno 618 GPU and a X15 LTE modem (Cat 15, downlink speeds up to 800Mbps). Either way, you get 8GB of RAM and 128GB storage. vivo’s Extended RAM feature promises to make the system feel like it has 3 extra gigs of RAM.
All three phones have 4,000 mAh batteries can be topped up quickly with support for 33W FlashCharge.
vivo V21 (and V21 5G) in Sunset Dazzle, Dusk Blue and Arctic White
The vivo V21 and V21 5G will be available soon in three colors: Sunset Dazzle, Dusk Blue and Arctic White. The vivo V21e comes with Diamond Flare and Roman Black.
vivo V21e in: Diamond Flare • Roman Black
In Malaysia, the vivo V21 and V21e can be pre-ordered today, the two will be available on May 5 at MYR 1,600 and MYR 1,200, respectively. The V21 5G isn’t coming to Malaysia.
Samsung has released a new software update for the Galaxy S21 Ultra 5G, which bumps up the Android security patch level on the flagship to May 1, 2021. Additionally, the new build improves the camera and enhances the Quick Share feature.
The new firmware carries version number G998BXXU3AUDA and requires a download of about 1.2GB. It’s currently seeding in Germany, and we expect the rollout to expand in other countries soon.
If you live in Germany and haven’t received the update yet, you can try checking for it manually by navigating to your smartphone’s Settings > Software update menu.
Oppo will introduce the K9 5G on May 6 in China, and the company has already confirmed the smartphone will come with a Snapdragon 768G SoC, 64MP triple camera, and 65W charging. Now we learn more about the K9 5G as the smartphone has been listed on Oppo’s Chinese website.
The Oppo K9 5G will sport a 6.43″ Samsung-made OLED having a 90Hz refresh rate and 180Hz touch sampling rate. The screen will also have a sixth-gen fingerprint scanner underneath for biometric authentication, with the punch hole in the upper-left corner housing a 32MP selfie camera.
The 64MP primary camera on the rear will be joined by an 8MP ultrawide module, with the third camera likely being a depth or macro unit.
Fueling the entire package will be a 4,300 mAh battery, which will go from flat to 100% in 35 minutes when charged with the 65W bundled adapter.
The Oppo K9 5G will have two color options, and JD.com revealed it will come in two memory configurations – 8GB/128GB and 8GB/256GB. The K9 5G’s pricing is unknown, but we’ll learn more about it and the availability next Thursday.
Apple is now rolling out iOS 14.5 to the iPhone alongside iPadOS 14.5 and watchOS 7.4. This is a pretty sizable update that brings a lot of new features but here’s a quick rundown of some of them.
The main new feature is that you can now unlock your iPhone with your Apple Watch if you are wearing a mask. A new ‘Unlock with Apple Watch’ option has been added in phone’s settings, which should cause your iPhone to unlock automatically if you are wearing a mask and also your Apple Watch. This feature requires you to have also updated to watchOS 7.4.
Another major new feature is App Tracking Transparency, which lets you control which apps are allowed to track your activity across other companies’ apps and websites for ads or sharing with data brokers. Once this update is installed, apps that have to track you now need to ask for your explicit permission before they can do so and with one click you can allow or deny them.
iOS 14.5 also adds support for AirTag. This includes activating the hardware features that let you track your AirTag device and also an updated Find My app that will help you locate it.
Siri has also received an update with more voice option. There are now 14 different voices from different regions and genders. Siri can now also announce incoming calls and caller name and if you’re wearing AirPods or compatible Beats headphones you can also answer hands-free. You can now also call your emergency contact using Siri.
iOS 14.5 will also perform a recalibration of your phone’s battery. This will show the battery’s health more accurately and can take a few weeks to complete. This feature is only available on the 11-series iPhones.
iOS 14.5 features
Other improvements in this update include new emoji, sharing lyrics through Apple Music, new Podcasts app, redesigned News app, improvements to 5G connectivity, support for Xbox Series X|S and PlayStation 5 controllers, and more.
Say hello to the Oppo Reno5 5G, a phone that Europeans can find at their local Amazon as the Find X3 Lite, and which aims to be provide the best value in the lineup.
It comes in a well-stocked box with a case, 65W charger, a sturdy USB cable and regular old 3.5mm earbuds.
Up front the Reno5 5G is one of the best reasons to buy it – the 6.43-inch 1080p AMOLED isn’t only high quality and high refresh rate at 90Hz, but it enables the phone’s compact form. At 172g the Oppo Reno5 5G is pleasingly light.
The Reno5 5G comes with Android 11 and Oppo’s fully-featured ColorOS 11.1, which adds niceties like pulling up your apps into a neat, accessible row near your fingertip when you can’t reach with your other hand. ColorOS is packed with other niceties – more on that in our full review.
The Oppo Reno5 5G has four imagers on the rear, but only two of real note – the 64MP main shooter and the 8MP ultrawide. The other two are a 2MP duo of depth and macro.
Front-side there’s a 32MP selfie camera, which features a bunch of smart shooting modes, but lacks autofocus.
Finally the 4,300mAh is capable of 65W fast charging, courtesy of SuperVOOC 2.0. All it takes for a full charge is 35 minutes.
We’ll test the charging speed as well as the battery endurance, along with just about everything else on the Oppo Reno5 5G in our full review. Stay tuned!
Yesterday marked the 36th anniversary of the first power-on of an Arm processor. Today, the company announced the deep-dive details of its Neoverse V1 and N2 platforms that will power the future of its data center processor designs and span up to a whopping 192 cores and 350W TDP.
Naturally, all of this becomes much more interesting given Nvidia’s pending $40 billion Arm acquisition, but the company didn’t share further details during our briefings. Instead, we were given a deep dive look at the technology roadmap that Nvidia CEO Jensen Huang says makes the company such an enticing target.
Arm claims its new, more focused Noverse platforms come with impressive performance and efficiency gains. The Neoverse V1 platform is the first Arm core to support Scalable Vector Extensions (SVE), bringing up to 50% more performance for HPC and ML workloads. Additionally, the company says that its Neoverse N2 platform, its first IP to support newly-announced Arm v9 extensions, like SVE2 and Memory Tagging, delivers up to 40% more performance in diverse workloads.
Additionally, the company shared further details about its Neoverse Coherent Mesh Network (CMN-700) that will tie together the latest V1 and N2 designs with intelligent high-bandwidth low-latency interfaces to other platform additives, such as DDR, HBM, and various accelerator technologies, using a combination of both industry-standard protocols, like CCIX and CXL, and Arm IP. This new mesh design serves as the backbone for the next generation of Arm processors based on both single-die and multi-chip designs.
If Arm’s performance projections pan out, the Neoverse V1 and N2 platforms could provide the company with a much faster rate of adoption in multiple applications spanning the data center to the edge, thus putting even more pressure on industry x86 stalwarts Intel and AMD. Especially considering the full-featured connectivity options available for both single- and multi-die designs. Let’s start with the Arm Neoverse roadmap and objectives, then dive into the details of the new chip IP.
Arm Neoverse Platform Roadmap
Image 1 of 15
(Image credit: Arm)
Image 2 of 15
(Image credit: Arm)
Image 3 of 15
(Image credit: Arm)
Image 4 of 15
(Image credit: Arm)
Image 5 of 15
(Image credit: Arm)
Image 6 of 15
(Image credit: Arm)
Image 7 of 15
(Image credit: Arm)
Image 8 of 15
(Image credit: Arm)
Image 9 of 15
(Image credit: Arm)
Image 10 of 15
(Image credit: Arm)
Image 11 of 15
(Image credit: Arm)
Image 12 of 15
(Image credit: Arm)
Image 13 of 15
(Image credit: Arm)
Image 14 of 15
(Image credit: Arm)
Image 15 of 15
(Image credit: Arm)
Arm’s roadmap remains unchanged from the version it shared last year, but it does help map out the steady cadence of improvements we’ll see over the next few years.
Arm’s server ambitions took flight with the A-72 in 2015, which was equivalent to the performance and performance-per-watt of a traditional thread on a standard competing server architecture.
Arm says its current-gen Neoverse N1 cores, which powers AWS Graviton 2 chips and Ampere’s Altra, equals or exceeds a ‘traditional’ (read: x86) SMT thread. Additionally, Arm says that, given N1’s energy efficiency, one N1 core can replace three x86 threads but use the same amount of power, providing an overall 40% better price-vs-performance ratio. Arm chalks much of this design’s success up to the Coherent Mesh Network 600 (CMN-600) that enables linear performance scaling as core counts increase.
Arm has revised both its core architecture and the mesh for the new Neoverse V1 and N2 platforms that we’ll cover today. Now they support up to 192 cores and 350W TDPs. Arm says the N2 core will take the uncontested lead over an SMT thread on competing chips and offers superior performance-per-watt.
Additionally, the company says that the Neoverse V1 core will offer the same performance as competing cores, marking the first time the company has achieved parity with two threads running on an SMT-equipped core. Both chips utilize Arm’s new CMN-700 mesh that enables either single-die or multi-chip solutions, offering customers plenty of options, particularly when deployed with accelerators.
Ts one would expect, Arm’s Neoverse N2 and V1 target hyperscale and cloud, HPC, 5G, and the infrastructure edge markets. Customers include Tencent, oracle Cloud with Ampere, Alibaba, AWS with Graviton 2 (which is available in 70 out of 77 AWS regions). Arm also has two exascale-class supercomputer deployments planned with Neoverse V1 chips: SiPearl “Rhea” and the ETRI K-AB21.
Overall, ARM claims that its Neoverse N2 and V1 platforms will offer best-in-class compute, performance-per-watt, and scalability over competing x86 server designs.
Arm Neoverse V1 Platform ‘Zeus’
Image 1 of 3
(Image credit: Arm)
Image 2 of 3
(Image credit: Arm)
Image 3 of 3
(Image credit: Arm)
Arm’s existing Neoverse N1 platform scales from the cloud to the edge, encompassing everything from high-end servers to power-constrained edge devices. The next-gen Neoverse N2 platform preserves that scalability across a spate of usages. In contrast, Arm designed the Neoverse V1 ‘Zeus’ platform specifically to introduce a new performance tier as it looks to more fully penetrate HPC and machine learning (ML) applications.
The V1 platform comes with a wider and deeper architecture that supports Scalable Vector Extensions (SVE), a type of SIMD instruction. The V1’s SVE implementation runs across two lanes with a 256b vector width (2x256b), and the chip also supports the bFloat16 data type to provide enhanced SIMD parallelism.
With the same (ISO) process, Arm claims up to 1.5x IPC increase over the previous-gen N1 and a 70% to 100% improvement to power efficiency (varies by workload). Given the same L1 and L2 cache sizes, the V1 core is 70% larger than the N1 core.
The larger core makes sense, as the V-series is optimized for maximum performance at the cost of both power and area, while the N2 platform steps in as the design that’s optimized for power-per-watt and performance-per-area.
Per-core performance is the primary objective for the V1, as it helps to minimize the performance penalties for GPUs and accelerators that often end up waiting on thread-bound workloads, not to mention to minimize software licensing costs.
Arm also tuned the design to provide exceptional memory bandwidth, which impacts performance scalability, and next-gen interfaces, like PCIe 5.0 and CXL, provide I/O flexibility (much more on that in the mesh section). The company also focused on performance efficiency (a balance of power and performance).
Finally, Arm lists technical sovereignty as a key focus point. This means that Arm customers can own their own supply chain and build their entire SoC in-country, which has become increasingly important for key applications (particularly defense) among heightened global trade tensions.
Image 1 of 2
(Image credit: Arm)
Image 2 of 2
(Image credit: Arm)
The Neoverse V1 represents Arm’s highest-performance core yet, and much of that comes through a ‘wider’ design ethos. The front end has an 8-wide fetch, 5-8 wide decode/rename unit, and a 15-wide issue into the back end of the pipeline (the execution units).
As you can see on the right, the chip supports HBM, DDR5, and custom accelerators. It can also scale out to multi-die and multi-socket designs. The flexible I/O options include the PCIe 5 interface and CCIX and CXL interconnects. We’ll cover the Arm’s mesh interconnect design a bit later in the article.
Additionally, Arm claims that, relative to the N1 platform, SVE contributes to a 2x increase in floating point performance, 1.8x increase in vectorized workloads, and 4x improvement in machine learning.
Image 1 of 7
Arm (Image credit: Arm)
Image 2 of 7
Arm (Image credit: Arm)
Image 3 of 7
Arm (Image credit: Arm)
Image 4 of 7
Arm (Image credit: Arm)
Image 5 of 7
Arm (Image credit: Arm)
Image 6 of 7
Arm (Image credit: Arm)
Image 7 of 7
Arm (Image credit: Arm)
One of V1’s biggest changes comes as the option to use either the 7nm or 5nm process, while the prior-gen N1 platform was limited to 7nm only. Arm also made a host of microarchitecture improvements spanning the front end, core, and back end to provide big speedups relative to prior-gen Arm chips, added support for SVE, and made accommodations to promote enhanced scalability.
Here’s a bullet list of the biggest changes to the architecture. You can also find additional details in the slides above.
Front End:
Net of 90% reduction in branch mispredicts (for BTB misses) and a 50% reduction in front-end stalls
V1 branch predictor decoupled from instruction fetch, so the prefetcher can run ahead and prefetch instruction into the instruction cache
Widened branch prediction bandwidth to enable faster run-ahead to (2x32b per cycle)
Increased capacity of the Dual-level BTB (Branch Target Buffers) to capture more branches with larger instruction footprints and to lower the taken branch latency, improved branch accuracy to reduce mispredicts
Enhanced ability to redirect hard-to-predict branches earlier in the pipeline, at fetch time, for faster branch recovery, improving both performance and power
Mid-Core:
Net increase of 25% in integer performance
Micro-Op (MOP) Cache: L0 decoded instruction cache optimizes the performance of smaller kernels in the microarchitecture, 2x increase in fetch and dispatch bandwidth over N1, lower-latency decode pipeline by removing one stage
Added more instruction fusion capability, improves performance end power efficiency for most commonly-used instruction pairs
OoO (Out of Order) window increase by 2X to enhance parallelism. Also increased integer execution bandwidth with a second branch execution unit and a fourth ALU
SIMD and FP Units: Added a new SVE implementation — 2x256b operations per cycle. Doubled raw execute capability from 2x128b pipelines in N1 to 4x128b in V1. Slide 10 — 4x improvement in ML performance
Back End:
45% increase to streaming bandwidth by increasing load/store address bandwidth by 50%, adding a third load data address generation unit (AGU – 50% increase)
To improve SIMD and integer floating point execution, added a third load data pipeline and improved load bandwidth for integer and vector. Doubled store bandwidth and split scheduling into two pipes
Load/store buffer window sizes increased. MMU capacity, allow for a larger number of cache translations
Reduce latencies in L2 cache to improve single-threaded performance (slide 12)
(Image credit: Arm)
This diagram shows the overall pipeline depth (left to right) and bandwidth (top to bottom), highlighting the impressive parallelism of the design.
Image 1 of 6
(Image credit: Arm)
Image 2 of 6
(Image credit: Arm)
Image 3 of 6
(Image credit: Arm)
Image 4 of 6
(Image credit: Arm)
Image 5 of 6
(Image credit: Arm)
Image 6 of 6
(Image credit: Arm)
Arm also instituted new power management and low-latency tools to extend beyond the typical capabilities of Dynamic Voltage Frequency Scaling (DVFS). These include the Max Power Mitigation Mechanism (MPMM) that provides a tunable power management system that allows customers to run high core-count processors at the highest possible frequencies, and Dispatch Throttling (DT), which reduces power during certain workloads with high IPC, like vectorized work (much like we see with Intel reducing frequency during AVX workloads).
At the end of the day, it’s all about Power, Performance, and Area (PPA), and here Arm shared some projections. With the same (ISO) process, Arm claims up to 1.5x IPC increase over the previous-gen N1 and a 70% to 100% improvement to power efficiency (varies by workload). Given the same L1 and L2 cache sizes, the V1 core is 70% larger than the N1 core.
The Neoverse V1 supports Armv8.4, but the chip also borrows some features from future v8.5 and v8.6 revisions, as shown above.
Arm also added several features to manage system scalability, particularly as it pertains to partitioning shared resources and reducing contention, as you can see in the slides above.
Image 1 of 8
(Image credit: Arm)
Image 2 of 8
(Image credit: Arm)
Image 3 of 8
(Image credit: Arm)
Image 4 of 8
(Image credit: Arm)
Image 5 of 8
(Image credit: Arm)
Image 6 of 8
(Image credit: Arm)
Image 7 of 8
(Image credit: Arm)
Image 8 of 8
(Image credit: Arm)
Arm’s Scalable Vector Extensions (SVE) are a big draw of the new architecture. Firstly, Arm doubled compute bandwidth to 2x256b with SVE and provides backward support for Neon at 4x128b.
However, the key here is that SVE is vector length agnostic. Most vector ISAs have a fixed number of bits in the vector unit, but SVE lets the hardware set the vector length in bits. However, in software, the vectors have no length. This simplifies programming and enhances portability for binary code between architectures that support different bit widths — the instructions will automatically scale as necessary to fully utilize the available vector bandwidth (for instance, 128b or 256b).
Arm shared information on several fine-grained instructions for the SVE instructions, but much of those details are beyond the scope of this article. Arm also shared some simulated V1 and N2 benchmarks with SVE, but bear in mind that these are vendor-provided and merely simulations.
ARM Neoverse N2 Platform ‘Perseus’
Image 1 of 17
(Image credit: Arm)
Image 2 of 17
(Image credit: Arm)
Image 3 of 17
(Image credit: Arm)
Image 4 of 17
(Image credit: Arm)
Image 5 of 17
(Image credit: Arm)
Image 6 of 17
(Image credit: Arm)
Image 7 of 17
(Image credit: Arm)
Image 8 of 17
(Image credit: Arm)
Image 9 of 17
(Image credit: Arm)
Image 10 of 17
(Image credit: Arm)
Image 11 of 17
(Image credit: Arm)
Image 12 of 17
(Image credit: Arm)
Image 13 of 17
(Image credit: Arm)
Image 14 of 17
(Image credit: Arm)
Image 15 of 17
(Image credit: Arm)
Image 16 of 17
(Image credit: Arm)
Image 17 of 17
(Image credit: Arm)
Here we can see the slide deck for the N2 Perseus platform, with the key goals being a focus on scale-out implementations. Hence, the company optimized the design for performance-per-power (watt) and performance-per-area, along with a healthier dose of cores and scalability. As with the previous-gen N1 platform, this design can scale from the cloud to the edge.
Neoverse N2 has a newer core than the V1 chips, but the company isn’t sharing many details yet. However, we do know that N2 is the first Arm platform to support Armv9 and SVE2, which is the second generation of the SVE instructions we covered above.
Arm claims a 40% increase in single-threaded performance over N1, but within the same power and area efficiency envelope. Most of the details about N2 mirror those we covered with V1 above, but we included the slides above for more details.
Image 1 of 20
(Image credit: Arm)
Image 2 of 20
(Image credit: Arm)
Image 3 of 20
(Image credit: Arm)
Image 4 of 20
(Image credit: Arm)
Image 5 of 20
(Image credit: Arm)
Image 6 of 20
(Image credit: Arm)
Image 7 of 20
(Image credit: Arm)
Image 8 of 20
(Image credit: Arm)
Image 9 of 20
(Image credit: Arm)
Image 10 of 20
(Image credit: Arm)
Image 11 of 20
(Image credit: Arm)
Image 12 of 20
(Image credit: Arm)
Image 13 of 20
(Image credit: Arm)
Image 14 of 20
(Image credit: Arm)
Image 15 of 20
(Image credit: Arm)
Image 16 of 20
(Image credit: Arm)
Image 17 of 20
(Image credit: Arm)
Image 18 of 20
(Image credit: Arm)
Image 19 of 20
(Image credit: Arm)
Image 20 of 20
(Image credit: Arm)
Arm provided the above benchmarks, and as with all vendor-provided benchmarks, you should take them with a grain of salt. We have also included the test notes at the end of the album for further perusal of the test configurations.
Arm’s SPEC CPU 2017 single-core tests show a solid progression from N1 to N2, and then a higher jump in performance with the V1 platform. The company also provided a range of comparisons against the Intel Xeon 8268 and an unspecified 40-core Ice Lake Xeon system, and the EPYC Rome 7742 and EPYC Milan 7763.
Coherent Mesh Network (CMN-700)
Image 1 of 5
(Image credit: Arm)
Image 2 of 5
(Image credit: Arm)
Image 3 of 5
(Image credit: Arm)
Image 4 of 5
(Image credit: Arm)
Image 5 of 5
(Image credit: Arm)
Arm allows its partners to adjust core counts, cache sizes, and use different types of memory, such as DDR5 and HBM and select various interfaces, like PCIe 5.0, CXL, and CCIX, requiring a very flexible underlying design methodology. Add in the fact that Neoverse can span from the cloud and edge to 5G, and the interconnect also has to be able to span a full spectrum of various power points and compute requirements. That’s where the Coherent Mesh Network 700 (CMN-700) steps in.
Arm focuses on security through compliance and standards, Arm open-source software, and ARM IP and architecture, all rolled under the SystemReady umbrella that serves as the underpinning of the Neoverse platform architecture.
Arm provides customers with reference designs based on its own internal work, with the designs pre-qualified in emulated benchmarks and workload analysis. Arm also provides a virtual model for software development too.
Customers can then take the reference design, choose between core types (like V-, N- or E-Series) and alter core counts, core frequency targets, cache hierarchy, memory (DDR5, HBM, Flash, Storage Class Memory, etc.), and I/O accommodations, among other factors. Customers also dial in parameters around the system-level cache that can be shared among accelerators.
There’s also support for multi-chip integration. This hangs off the coherent mesh network and provides plumbing for I/O connectivity options and multi-chip communication accommodations through interfaces like PCIe, CXL, CCIX, etc.
The V-Series CPUs address the growth of heterogeneous workloads by providing enough bandwidth for accelerators, support for disaggregated designs, and also multi-chip architectures that help defray the slowing Moore’s Law.
These types of designs help address the fact that the power budget per SoC (and thus thermals) is increasing, and also allow scaling beyond the reticle limits of a single SoC.
Additionally, I/O interfaces aren’t scaling well to smaller nodes, so many chipmakers (like AMD) are keeping PHYs on older nodes. That requires robust chip-to-chip connectivity options.
(Image credit: Arm)
Here we can see the gen-on-gen comparison with the current CMN-600 interface found on the N1 chips. The CMN-700 mesh interface supports four times more cores and system-level cache per die, 2.2x more nodes (cross points) per die, 2.5x memory device ports (like DRAM, HBM) per die, and 8x the number of CCIX device ports per die (up to 32), all of which supplies intense scalability.
Image 1 of 4
(Image credit: Arm)
Image 2 of 4
(Image credit: Arm)
Image 3 of 4
(Image credit: Arm)
Image 4 of 4
(Image credit: Arm)
Arm improved cross-sectional bandwidth by 3X, which is important to provide enough bandwidth for scalability of core counts, scaling out with bandwidth-hungry GPUs, and faster memories, like DDR5 and HBM (the design accommodates 40 memory controllers for either/or DDR and HBM). Arm also has options for double mesh channels for increased bandwidth. Additionally, a hot spot reroute feature helps avoid areas of contention on the fabric.
The AMBA Coherent Hub Interface (CHI) serves as the high-performance interconnect for the SoC that connects processors and memory controllers. Arm improved the CHI design and added intelligent heuristics to detect and control congestion, combine operations to reduce transactions, and conduct data-less writes, all of which help reduce traffic on the mesh. These approaches also help with multi-chip scaling.
Memory partitioning and monitoring (MPAM) helps reduce the impact of noisy neighbors on system-level cache and isolates VMs to keep them from hogging system level cache (SLC). Arm also extends this software-controlled system to the memory controller as well. All this helps to manage shared resources and reduce contention. The CPU, accelerator, and PCIe interfaces all have to work together as well, so the design applies the same traffic management techniques between those units, too.
Image 1 of 4
(Image credit: Arm)
Image 2 of 4
(Image credit: Arm)
Image 3 of 4
(Image credit: Arm)
Image 4 of 4
(Image credit: Arm)
The mesh supports multi-chip designs through CXL or CCIX interfaces, and here we see a few of the use cases. CCIX is typically used inside the box or between the chips, be that heterogenous packages, chiplets, or multi-socket. In contrast, CXL steps in for memory expansion or pools of memory shared by multiple hosts. It’s also used for coherent accelerators like GPUs, NPUs, and SmartNICs, etc.
Slide 14 shows an example of a current connection topology — PCIe connects to the DPU (Data Plane Unit – SmartNic), which then provides the interconnection to the compute accelerator node. This allows multiple worker nodes to connect to shared resources.
Slide 15 shows us the next logical expansion of this approach — adding disaggregated memory pools that are shared between worker nodes. Unfortunately, as shown in slide 16, this creates plenty of bottlenecks and introduces other issues, such as spanning the home nodes and system-level cache across multiple dies. Arm has an answer for that, though.
Image 1 of 4
(Image credit: Arm)
Image 2 of 4
(Image credit: Arm)
Image 3 of 4
(Image credit: Arm)
Image 4 of 4
(Image credit: Arm)
Addressing those bottlenecks requires a re-thinking of the current approaches to sharing resources among worker nodes. Arm designed a multi-protocol gateway with a new AMBA CXS connection to reduce latency. This connection can transport CCIX 2.0 and CXL 2.0 protocols much faster than conventional interconnections. This system also provides the option of using a Flit data link layer that is optimized for the ultimate in low-latency connectivity.
This new design can be tailored for either socket-to-socket or multi-die compute SoCs. As you can see to the left on Slide 17, this multi-protocol gateway can be used either with or without a PCIe PHY. Removing the PCIe PHY creates an optimized die-to-die gateway for lower latency for critical die-to-die connections.
Arm has also devised a new Super Home Node concept to accommodate multi-chip designs. This implementation allows composing the system differently based on whether or not it is a homogenous design (direct connections between dies) or heterogeneous (compute and accelerator chiplets) connected to an I/O hub. The latter design is becoming more attractive because I/O doesn’t scale well to smaller nodes, so using older nodes can save quite a bit of investment and help reduce design complexity.
Thoughts
ARM’s plans for a 30%+ gen-on-gen IPC growth rate stretch into the next three iterations of its existing platforms (V1, N2, Poseidon) and will conceivably continue into the future. We haven’t seen gen-on-gen gains in that range from Intel in recent history, and while AMD notched large gains with the first two Zen iterations, as we’ve seen with the EPYC Milan chips, it might not be able to execute such large generational leaps in the future.
If ARM’s projections play out in the real world, that puts the company not only on an intercept course with x86 (it’s arguably already there in some aspects), but on a path to performance superiority.
Wrapping in the amazingly well-thought-out coherent mesh design makes these designs all the more formidable, especially in light of the ongoing shift to offloading key workloads to compute accelerators of various flavors. Additionally, bringing complex designs, like chiplet, multi-die, and hub and spoke designs all under one umbrella of pre-qualified reference designs could help spur a hastened migration to Arm architectures, at least for the cloud players. That attraction of licensable interconnections that democratize these complex interfaces is definitely yet another arrow in Arm’s quiver.
Perhaps one of the most surprising tidbits of info that Arm shared in its presentations was one of the smallest — a third-party firm has measured that more than half of AWS’s newly-deployed instances run on Graviton 2 processors. Additionally, Graviton 2-powered instances are now available in 70 out of the 77 AWS regions. It’s natural to assume that those instances will soon have a newer N2 or V1 architecture under the hood.
This type of uptake, and the economies of scale and other savings AWS enjoys from using its own processors, will force other cloud giants to adapt with their own designs in kind, perhaps touching off the type of battle for superiority that can change the entire shape of the data center for years to come. There simply isn’t another vendor more well-positioned to compete in a world where the hyperscalers and cloud giants battle it out with custom silicon than Arm.
Razer’s new $69.99 Orochi V2 is a wireless gaming mouse that promises extremely long battery life. It can apparently last up to 950 hours on a single AA battery when it’s in Bluetooth mode or up to 425 hours if you toggle its wireless switch to use the 2.4GHz Hyperspeed mode that can deliver lower-latency performance.
Alternatively, you can use an AAA battery for a slightly lighter weight. Razer says you’ll get approximately a third of the longevity this way compared to an AA battery. Still, it’s nice that either size of battery can power this mouse for many, many hours. Razer includes a USB-A dongle near the battery slots, which is accessible by lifting up on the mouse’s magnetically attached shell.
Good battery life is useful for any kind of workload, but it’s especially nice to have for gaming, which is what the Orochi V2 was designed for. This mouse feels similar in some ways to the Razer Basilisk X Hyperspeed — another budget-friendly battery-powered mouse with two wireless modes. The Orochi V2 has a textured scroll wheel, angular main mouse buttons that are slightly concave to keep your fingers steady in-game, and two thumb buttons. It’s a smaller mouse overall than the Basilisk X Hyperspeed, yet Razer built it to cater to several grip styles, including claw, palm, and fingertip grips. It is symmetrically designed, though not ambidextrous. A concave thumb rest and the two thumb buttons cater to right-handed gamers.
It can hold a AA battery or a AAA battery but not both.Image: Razer
As for the specs, the Orochi V2 comes in matte black or white and weighs around 71 grams with a AA battery or 64 grams with a AAA battery. It features mechanical mouse switches that have a 60-million click lifespan and uses Razer’s 18K DPI 5G optical sensor. The mouse’s underside features PTFE feet that help it glide easily across a mousepad. Near the scroll wheel, the Orochi V2 has a DPI switcher to adjust sensitivity. It doesn’t have any LEDs, aside from the power indicator next to the DPI-switching button.
The Orochi V2 in black is available at Razer and Walmart. The white-colored model is selling at Amazon, Best Buy, and Razer. If you want a different color or design, Razer is launching a site where you can create an Orochi V2 with a custom look, picking from (according to the company) “over 100” different designs. The customized model costs $89.99 — a $20 premium over the standard option.
A sampling of the designs you can get on the Orochi V2 for an extra $20.Image: Razer
The company has also released universal grip tape for your tech. It’s a $9.99 kit filled with different sizes of textured tape that you can stick to a mouse, keyboard, controller, or anything else you want to add some grip to. That’s available on Amazon now.
(Pocket-lint) – The Google Pixel 4 and Pixel 4 XL were announced in October 2019, succeeded by the Google Pixel 5 in September 2021. There’s also the Pixel 4a and the Pixel 4a 5G to consider. If you’re choosing between the Pixel 4 and 4 XL and you want to know which might be the right choice for you though, you’re in the right place.
This is a comparison of the Pixel 4 against the Pixel 4 XL. You can also read our Pixel 4 vs Pixel 3 feature to find out how they compare to their predecessors and our Pixel 5 vs Pixel 4 feature to see how they compare to their successors.
squirrel_widget_168586
What’s the same?
Design
Rear and front camera
Processor/RAM/Storage
Software and features
The Google Pixel 4 and 4 XL both feature the same design – aside from physical footprint – with a contrasting power button and three colour options. They both have a black frame, a glass front and rear and a rear camera system within a square housing. They also both have gesture controls and Face unlock thanks to Google’s Soli motion-sensing radar chip.
The two devices also feature a bezel at the top of their displays and they both run on Qualcomm’s Snapdragon 855 platform. Neither offers microSD support, as has been the case on all Pixel devices, and neither has a 3.5mm headphone jack.
The software experience is identical, with both launching with Android 10.
What’s different between the Pixel 4 and Pixel 4 XL?
Plenty transfers between little and large in the case of the Pixel 4 devices, but there are a few differences too.
Physical size
Pixel 4: 147.1 x 68.8 x 8.2mm
Pixel 4 XL: 160.4 x 75.1 x 8.2mm
Unsurprisingly, Google Pixel 4 and Pixel 4 XL differ in terms of physical size.
The Google Pixel 4 measures 147.1 x 68.8 x 8.2mm and weighs 162g, while the Google Pixel 4 XL measures 160.4 x 75.1 x 8.2mm and weighs 193g.
Display
Pixel 4: 5.7-inches, Full HD+, 90Hz
Pixel 4 XL: 6.3-inches, Quad HD+, 90Hz
As with the physical footprint, the display size differs between the Pixel 4 and 4 XL. The Pixel 4 has a 5.7-inch screen, while the Pixel 4 XL offers a 6.3-inch screen.
The Pixel 4 has a Full HD+ resolution, while the Pixel 4 XL has a Quad HD+ resolution, meaning the larger device offers a sharper screen. Both have a 90Hz refresh rate though, both are OLED panels and both support HDR.
Battery
Pixel 4: 2800mAh
Pixel 4 XL: 3700mAh
The Pixel 4 and Pixel 4 XL offer different battery capacities, like the older the Pixel 3 and 3 XL. The Pixel 4 has a 2800mAh battery, while the Pixel 4 XL has a 3700mAh battery.
squirrel_widget_168578
Conclusion
The Google Pixel 4 and 4 XL offer identical designs, hardware and software experiences, though there are differences in battery capacities, price, displays and footprint sizes.
You don’t compromise much by opting for the smaller device though, and you save a few pennies too – especially now these models have been succeeded. Some will want the higher resolution display and larger battery capacity offered by the XL model, but if you aren’t bothered by those, the Pixel 4 is a great option.
(Pocket-lint) – The Xiaomi Mi 11 range spans a significant spectrum from top-tier flagship, in the Mi 11 Ultra, to the standard Mi 11, down to the more entry level – which is where this, the Mi 11 Lite 5G, finds itself.
Despite plonking ‘Lite’ into its name, however, the Mi 11 Lite 5G really is not a low-power phone by any means. It’s just not as crazy-powerful as the upper echelons in the range. The second clue to that regard is the ‘5G’ aspect of the name – because, yes, there’s also speedy connectivity.
So if you’re not looking to spend a fortune on a phone, want 5G connectivity, and having a slimmer and easier-to-manage handset is high up your list of appeals, the Xiaomi Mi 11 Lite 5G ticks a lot of boxes. But then so do a bunch of competitors. So can this entry-level 5Ger deliver?
Design & Display
Display: 6.55-inch AMOLED panel, 90Hz refresh, 1080 x 2400 resolution
Finish options: Truffle Black, Mint Green, Citrus Yellow
Dimensions: 160.5 x 75.7 x 6.8mm / Weight: 157g
Side-mounted fingerprint scanner
No 3.5mm jack
Upon pulling the Mi 11 Lite 5G from its box we let out a rare gasp. Because, shown here in its apparent ‘Mint Green’ finish – it looks more ‘Bubblegum’ to us, which is the name for the non-5G variant – this handset looks really fresh and standout. Very dapper indeed.
That’s partly because Xiaomi has redesigned the range, so the Mi 11 Lite looks way more evolved than the previous 10T Lite version. Look at those side-by-side and the older model looks rather dated – it’s quite a stark difference. Yet there’s mere months between them in terms of release cycle.
That said, the Mi 11 Lite 5G is only a little like other Mi 11 handsets in terms of design. The cameras are far different to the Ultra’s “megabump”, arranged in a really neat format that, although similar to the Mi 11, doesn’t protrude to the same degree from the rear.
The rear finish is good at resisting fingerprints too, which is a breath of fresh air (minty fresh, eh!), while the branding is subtle and nicely integrated.
Motorola’s new Moto G9 Plus is a stunner of a phone – find out why, right here
By Pocket-lint Promotion
·
But above all else, it’s the Mi 11 Lite 5G’s thickness that’s its biggest take-away point. By which we mean thinness: because this handset is far slimmer than, well, pretty much anything we’ve used for months and months. We can’t think of a slimmer 5G smartphone. That, for us, has bags of appeal – it’s been really refreshing not carting a brick around in the pocket for the couple of weeks we’ve been using this phone.
Such a svelte design means the 3.5mm headphone jack has been binned, though, so it’s wireless connectivity only in that regard. But we can take that – it makes the design look more enclosed and complete anyway. There’s also no under-display fingerprint scanner here, with a side-mounted one in the power button a perfectly acceptable alternative – that operates speedily and we’ve got very much used to using it.
The display, at 6.55-inches, is still large despite the phone’s overall trim frame. It’s flat, with the phone body curving gently at the edges to make it really comfortable to hold. And there’s no teardrop notch to cry about this time around either – it’s a single punch-hole one to the upper corner, which is fairly inconspicuous.
That screen, an AMOLED panel, delivers on colour, brightness and verve, while a 90Hz refresh rate can deliver a little added smoothness to proceedings. There’s not a 120Hz option here – kind-of odd, as the 10T Lite did have that – but, really, most eyes aren’t going to tell the difference. We’d take the battery life gains every time instead, thanks.
Performance & Battery
Processor: Qualcomm Snapdragon 780G, 8GB RAM
Software: MIUI 12 over Google Android 11 OS
Battery: 4250mAh, 33W fast-charging
Storage: 128GB/256GB, microSD
Speaking of battery, that’s the first thing we assumed would be poor in the Mi 11 Lite 5G – because of how slim it is. But how wrong we were. For starters the 4,250mAh capacity cell is pretty capacious – and in our hands was easily able to deliver 16 hours a day with around 25 per cent battery or more remaining.
That’s been irrelevant of what we’ve asked the phone to do in a given day. Strava tracking for an hour and an hour of gaming in the evening, in addition to hours of screen time, calls and so forth. It’s no problem for this device. Note, however, that we’ve been unable to locate a 5G signal area during testing – lockdown and all that – so whether that would adversely affect battery life is for debate. What we do see in the settings, however, is a 5G option to toggle the connectivity off when it’s not needed, to further extend battery life.
However, while battery life ticks along just fine, part of the reason is down to the rather hardcore software approach. Xiaomi’s MIUI 12 – skinned over the top of Google’s Android 11 operating system – by default has a lot of “off” switches selected. Seriously, MIUI is hell-bent on ensuring battery lasts and lasts – sometimes to the detriment of the experience and use of apps.
As such, you’ll need to investigate individual apps within the settings and permit them to self wake as and when they need, removing any automated battery restrictions from the important ones that you have and would, say, expect push notifications from. In the past we’ve had MIUI cause delays with notifications in other Xiaomi phones. In the Mi 11 Lite 5G, however, that’s been no problem whatsoever – perhaps because we’re so used to it and in setting the software in how we want to conduct our business; or, perhaps, because Xiaomi has sorted that issue out in an incremental update!
Otherwise the software is pretty robust. There are some oddities, such as an additional Xiaomi store as an addition to Google Play, but the two hardly interfere too much. And having copied over a bumper crop of apps, it’s clear to see that there are Xiaomi pre-install favourites and various not-needed staples – browsers, calendars, that kind of stuff – that just clogs up the home screen to start with, but is easily replaced with Chrome and your other favourites.
Regarding the phone’s innards, there’s a Qualcomm Snapdragon 780G platform handling proceedings, putting the Mi 11 Lite 5G one step down from the top-tier 800 series platform. Does that really matter? We’ve not found it to at all. From general user interface use, to app opening time, fluidity has been high throughout.
Besides, a 700 series chipset is more than good enough to run your more demanding favourites too. We’ve been plugging away at South Park: Phone Destroyer and PUBG: Mobile without hindrance, showing just how good the balance of power and battery life can be in devices such as this.
Wide-angle (0.5x): 8MP, f/2.2, 1.12µm, 119-degree angle of view
Macro: 5MP, f/2.4
Single front-facing punch-hole selfie camera: 20MP, f/2.2
Buy a ‘Lite’ phone and you’re never going to expect too much from the cameras, right? However, Xiaomi has done a reasonable job here of balancing things out. For starters all three lenses are actually useful – there’s not a lens here for the sake of number count, like with so much of the competition.
The main 64-megapixel sensor uses four-in-one processing to output 16-megapixel shots as standard, which hold enough colour and detail. Even in low-light conditions we’ve found the quality to hold up fairly well, too, so this sensor delivers the goods.
It’s a shame that there’s no optical stabilisation on the main lens, because holding it steady – especially when shooting Night Mode shots – is tricky and can result in a little softeness in dim conditions if you’re not careful.
Pocket-lint
: Wide-angle – full shotWide-angle – full shot
The wide-angle, however, is a weaker sensor. It’s just 8-megapixels in resolution, can’t deliver the fidelity of the main one by any means, and displays some blur to the edges. That’s pretty common for wide-angle cameras, sure, but there are better iterations around. Still, there’s practical use from a sensor such as this, so it’s a positive to have it rather than not.
Last up out of the trio is a macro sensor. Now, typically, these are throwaway afterthoughts. But, actually, the one on this Mi handset is acceptable – probably because it’s a 5-megapixel sensor, not the 2-megapixel type that too many other budget handsets opt for. That means images are of a usable scale, and you’ll get a little extra something out of super close-up shots from this sensor. We doubt you’ll use it a lot, though, as it’s hardly a practical everydayer, plus its activation is tucked away in settings – but there’s fun to be had from it nonetheless.
What we like about the Mi 11 Lite 5G’s camera setup is that it’s not trying to oversell you a bunch of pointless lenses. It doesn’t protrude five miles from the back of the phone, either, delivering a neat-looking handset that, while hardly reaching for the stars in what it can do, is perfectly capable. And, compared to the likes of the Moto G100, for example, the Xiaomi actually has the upper hand in its image quality delivery.
Verdict
Although the Xiaomi Mi 11 Lite 5G looks and feels different to the rest of the Mi 11 family, there’s something refreshing about its design. It’s really slim, light, and that colour finish looks super. We can’t think of a slimmer, tidier-looking 5G handset – which makes this something of a unique proposition.
Despite being called a ‘Lite’ phone, it shouldn’t be seen entirely in that regard either. With the Qualcomm Snapdragon 780G handling everything, there’s ample power to keep that 90Hz AMOLED screen ticking along, for battery life to last surprisingly long – we didn’t expect it, given the trim design – and software that, if you tend to it with a bit of pruning from the off, has been more robust here than many other Xiaomi handsets we’ve seen in the recent past.
However, forego the 5G need, and there are lots of cheaper competitors that might also appeal, such as the Redmi Note 10 Pro. Similar grade handsets, such as the Moto G100, may also appeal – but, as far as we understand it, the Xiaomi undercuts that device’s price point, asserting its position as one of the top dogs in the affordable 5G market.
Also consider
Moto G100
A near-ish comparison in that there’s 5G and gaming-capable power for less than a flagship price. We prefer the Moto’s software, but the Xiaomi’s design has the upper hand in our view.
Apple has begun rolling out iOS and iPadOS 14.5. The latest software update includes the new App Tracking Transparency feature, which lets users decide whether to allow apps to track their activity “across other companies’ apps and websites” for advertising purposes. A pop-up will now appear whenever apps are designed to share your activity in this way. Facebook has heavily criticized Apple over App Tracking Transparency, claiming that it presents “a false tradeoff between personalized ads and privacy.” The new option could have a detrimental impact on Facebook’s ad business.
Perhaps more important to day-to-day iPhone usage, iOS 14.5 also includes a very helpful and timely new trick: if you own an Apple Watch, you can set your iPhone to automatically unlock without requiring a Face ID match or passcode as long as Apple’s smartwatch is on your wrist. This is designed to make getting into your phone that much quicker while we’re all still wearing face masks so frequently throughout the day. Installing watchOS 7.4 is necessary for this feature to work; that update is also available as of today.
iOS and iPadOS 14.5 include a ton of new emoji with a focus on inclusivity. The update adds the ability to watch Apple Fitness Plus workouts on a TV with AirPlay 2. Apple’s Podcasts app is getting a new design and optional subscriptions. The latest video game controllers for the PS5 and Xbox Series X / S are now supported on the iPhone and iPad as of this update. And all iPhone 12 models will allow for 5G connectivity in dual-SIM mode in more countries. Starting with the 14.5 update, Apple will no longer default to a female-sounding voice for its Siri assistant. Instead, you’ll be prompted to choose your preferred voice during device setup. Apple has a post up with all of the miscellaneous improvements and additions.
iOS and iPadOS 14.5 is rolling out to iPhone and iPad users now; you can check the “software update” section in settings to begin the update process right away.
Google seems to have accidentally shared a photo sample from its upcoming Pixel 5A, giving us some hints about what to expect from the barely announced device. The photo appeared in an album posted alongside a blog post about Google’s HDR+ Bracketing technology, which aims to reduce noise in HDR photos (via Android Police). The EXIF data for most of the photos said they were captured by existing Pixel phones including the Pixel 5, Pixel 4A 5G, Pixel 4, and Pixel 4 XL, but in among them was one image apparently taken with a Pixel 5A.
Google recently confirmed the existence of the Pixel 5A 5G in response to rumors that the device had been cancelled. However, beyond confirming that the device will be available later this year in the US and Japan, it didn’t offer any more details about the phone’s specs or cameras.
The image labeled as coming from a Pixel 5A has since been removed from the album, but offered several details about the camera performance of the upcoming device while it was up. First is that it appears to have been taken with an ultrawide camera, which corroborates previous reports that the 5A will have two rear cameras — a main camera and an ultrawide. That’s similar to the Pixel 4A 5G, while the Pixel 4A had just the one rear camera.
A screenshot of the photo’s EXIF data before it was removed.Screenshot: Google Photos
Its resolution is also listed as 12.2 megapixels, which is similar to the photos we saw from the Pixel 5. Although the sensor in the Pixel 5’s ultrawide camera is technically 16 megapixels, it produces 12.2-megapixel shots by default. The 5A’s EXIF data also shows it has the same f/2.2 aperture as the 5. Given that the photo was attached to a blog post about HDR+ Bracketing, it seems likely that the 5A will also offer support for the technology.
Combined with previous rumors, it looks like the Pixel 5A could be a very similar device to last year’s Pixel 5. Reports suggest it’ll use the same Snapdragon 765G processor, and have a similar design with a 6.2-inch OLED display with a hole-punch selfie camera. Like Google’s previous A-series devices, however, the rear panel is expected to be made of plastic rather than glass, and the phone will also reportedly feature a 3.5mm headphone jack.
According to the leaked photo’s EXIF data, the photo itself was taken last October just before the Pixel 5 was released. Without official confirmation from Google there’s no guarantee it’s representative of the 5A’s final camera hardware, but the fact that the photo has now been removed suggests it wasn’t a simple labeling mistake.
If you buy something from a Verge link, Vox Media may earn a commission. See our ethics statement.
If a $100 budget phone is the fast-food dollar menu and a $1,000 flagship is a steakhouse dinner, then the Samsung Galaxy A52 5G sits comfortably halfway between the two: the laid-back all-day cafe with surprisingly tasty food.
It’s good. More importantly, it’s good where it matters. Sure, you have to order your food at the counter and get your own water refills, but it’s worth it because brunch is fantastic and the prices are reasonable.
The A52 5G is the highest-specced of the budget A-series Galaxy phones we’ll see in the US this year, offering all of the basics for its $499 price tag along with a few good extras. Its 6.5-inch screen comes with a fast 120Hz refresh rate that’s scarce at this price point. Its main camera includes optical image stabilization, something I missed when I used the more expensive OnePlus 9. The A52 5G is rated IP67 waterproof for some extra peace of mind. And hey, there’s still a headphone jack! In this economy!
Still, this isn’t a flagship, and costs had to be cut somewhere. The device’s frame and back panel are plastic, and while I like the matte finish on the back, there’s a certain hollowness when you tap on it that’s not very reassuring. There’s also no telephoto to complement the wide and ultrawide cameras, just digital zoom plus a depth sensor and macro camera of dubious usefulness.
The important stuff is here, though. Samsung has the A52 5G on its list for monthly OS updates currently, and it says it will offer three years of major Android OS updates and at least some security support for four years. That will go a long way toward making the most out of your investment in this phone, and it will help you take advantage of its headline feature: 5G — Sub-6GHz, specifically, with hardware-level support for the C-band frequencies carriers will start using in 2022.
It’s getting more common to see 5G offered in midrange and budget phones, but in this country, it’ll be a couple more years before our 5G networks are truly good. Healthy device support for the next few years makes it more likely that the A52 5G will actually last long enough to make it to that 5G promised land.
The A52 5G offers solid everyday performance with a Snapdragon 750G chipset and 6GB of RAM.
Samsung Galaxy A52 5G performance and screen
The A52 5G uses a Snapdragon 750G processor with 6GB of RAM, and the combination feels like a good fit here. You can certainly push it out of its comfort zone with heavier tasks like webpages with JavaScript, and I noticed it hesitating a moment too long when opening the camera app from the lock screen. But for day-to-day tasks and social media scrolling, it keeps up well.
As in last year’s model, the screen is where the A52 5G (and Samsung generally) really stand out. This is a 6.5-inch 1080p OLED panel that’s rich, bright, and generally lovely to look at. Plus, it offers all of the velvety smoothness that comes with its 120Hz refresh rate. Swiping between home screens, opening apps, scrolling through Twitter — it all just feels nicer with a fast refresh rate.
Even considering the additional power needed for the 120Hz screen, the A52 5G’s 4,500mAh battery consistently lasted well into the next day in my use. I managed to get two full days out of it when I forgot to charge it overnight and decided to embrace chaos and just plow through on the remaining charge. This was with light to moderate use, and I was down to low double-digit battery percentage by the end of day two, but my gamble paid off.
One feature I continue to fight a losing battle with on the A52 5G is the in-display optical fingerprint sensor. I’ve been chastised by the phone many times for not leaving my finger on the sensor long enough, and I almost always need at least two tries to get it to register. That hit rate goes down significantly outside in bright light.
These problems aren’t unique to this device, and you can just opt to use (less secure) facial recognition or a plain old PIN to lock and unlock the phone. But there are nicer in-display fingerprint readers in pricier phones like the OnePlus 9 and Samsung’s own S21, so it’s a trade-off to be aware of.
The Galaxy A52 5G ships with Android 11, which is great. The less good news is, as we saw in the S21 devices earlier this year, Samsung’s latest take on the OS stuffs a lot of unwanted apps, ads, and general clutter into the UI. I see enough ads throughout my day as it is, and I do not appreciate seeing one more when I check the weather on my phone’s own weather app.
If there’s a positive way to look at this situation, it’s that it feels more forgivable on a budget phone than on a $1,000-plus flagship. But I’d rather not have the ads at all. If you buy the similarly priced Pixel 4A 5G, you give up a lot of other features from the A52 5G, but you get an ad-free experience.
Housed in the rear camera bump are a standard wide, ultrawide, macro, and depth sensor.
Samsung Galaxy A52 5G camera
The A52 5G includes three rear cameras, plus a 5-megapixel depth sensor. You get a 64-megapixel standard wide with OIS, 12-megapixel ultrawide, and the seemingly obligatory 5-megapixel macro camera. There’s also a front-facing 32-megapixel selfie camera.
Taken with 2x digital zoom
Taken with ultrawide
Taken with ultrawide
The 64-megapixel main camera produces 16-megapixel images in its standard photo mode that are bright with the very saturated colors you’d expect from a Samsung phone. Sometimes the look is pleasant, but more often than not, it’s a little much for my taste. The good news is that this sensor is capable of capturing lots of fine detail in good lighting, and it even does well in dim to very low-light conditions.
I put its night mode up against the Google Pixel 4A, which is still the low-light champ in the midrange class. There’s more noise visible in the A52 5G’s night mode shot, and details have a watercolory look, but while the 4A hangs on to its title, the A52 5G is quite close behind.
Left: Galaxy A52 night mode. Right: Pixel 4A night mode.“,”image_left”:{“ratio”:”*”,”original_url”:”https://cdn.vox-cdn.com/uploads/chorus_asset/file/22465175/samsung_night_crop.jpg”,”network”:”verge”,”bgcolor”:”white”,”pinterest_enabled”:false,”caption”:null,”credit”:null,”focal_area”:{“top_left_x”:0,”top_left_y”:0,”bottom_right_x”:2040,”bottom_right_y”:1580},”bounds”:[0,0,2040,1580],”uploaded_size”:{“width”:2040,”height”:1580},”focal_point”:null,”asset_id”:22465175,”asset_credit”:null,”alt_text”:””},”image_right”:{“ratio”:”*”,”original_url”:”https://cdn.vox-cdn.com/uploads/chorus_asset/file/22465178/pixel_night_crop.jpg”,”network”:”verge”,”bgcolor”:”white”,”pinterest_enabled”:false,”caption”:null,”credit”:null,”focal_area”:{“top_left_x”:0,”top_left_y”:0,”bottom_right_x”:2040,”bottom_right_y”:1580},”bounds”:[0,0,2040,1580],”uploaded_size”:{“width”:2040,”height”:1580},”focal_point”:null,”asset_id”:22465178,”asset_credit”:null,”alt_text”:””},”credit”:null}” data-cid=”apps/imageslider-1619271003_9454_116978″>
Left: Galaxy A52 night mode. Right: Pixel 4A night mode.
The Pixel 4A is still the better camera in good lighting, too, but the differences are more subjective here. The 4A goes for more subdued color rendering, and the A52 5G’s images lack a little contrast in comparison.
So the A52 5G can’t beat the generation-old imaging tech in the 4A, but that might say more about the Pixel than anything else. Aside from that, the A52 5G turns in good all-around camera performance. Images from the ultrawide sometimes have a little cooler color cast but are generally good. The selfie camera offers two zoom settings: a slightly cropped-in standard wide view and an ever-so-slightly wider angle. The “focal length” difference between the two is almost laughably small.
At its default settings, the selfie camera does a fair amount of face smoothing and brightening. I don’t think it quite crosses the line into hamcam territory, but it certainly has that telltale “maybe it’s AI, maybe it’s Maybelline” smoothed look to it.
If you want to go full hamcam, there’s a new mode just labeled “fun” in the camera app with AR face filters brought to you by Snapchat. There’s a different selection of them every day, and you don’t need a Snapchat account to use or share them.
I’m tempted to dismiss them as “for the youths,” but maybe this is really for the olds like me who would rather not join another social platform if I can possibly avoid it, thank you very much. At last, I can transform my face into a piece of broccoli and share it with the world without logging in to Snapchat — three years after the kids have all moved on to something else. Anyway, it’s there, it works, and you can indeed turn your face into broccoli.
Good hardware and healthy software support make the A52 5G worth spending a little more on.
There’s a lot that the Galaxy A52 5G gets right. Maybe the most important feature is one that sounds much less exciting than cool headline specs: security updates for at least the next few years. At $500, this is the higher end of the budget market, but a few extra hundred dollars is likely easier to swallow if you know you’ll get a couple more years out of your investment.
Samsung has invested in hardware in all the right places: the 120Hz screen makes for an elevated user experience, battery life is good, camera performance is strong, and a healthy processor / chipset combination handles daily tasks well.
What I didn’t love — the cluttered software, fussy fingerprint sensor, a tendency toward oversaturated color in photos — feels more forgivable when the phone gets the nonnegotiable stuff right. The Pixel 4A 5G is probably this device’s closest competition, and it beats the A52 5G on camera quality and a cleaner UI, but it’s a smaller device without a fancy fast refresh rate screen. Depending on how you feel about either of those things, the 4A 5G might be the better pick for you.
In any case, the A52 5G is a good midrange phone today. But just as importantly, it will be a good phone a few years from now. With solid hardware and a software support system to back it up, this is a pricier budget phone that’s worth budgeting a little extra for.
Apple’s new Tile-like AirTags, long-rumored and finally announced at this week’s Spring Loaded event, are now available for preorder on Apple’s website. The small circular trackers work with Apple’s “Find My” app on iOS and have a built-in speaker, accelerometer, Bluetooth LE, and a replaceable battery. They cost $29 for one set or $99 for a four-pack.
Apple says the AirTags’ battery should be good for a year. They should start delivering between May 3rd and May 5th.
The existence of AirTags first became known nearly two years ago, in copies of the iOS 13 beta. Apple accidentally confirmed the AirTags name in a support video last year that has since been deleted.
Also revealed at Spring Loaded was the new purple iPhone 12. It’s identical to the other colors of the iPhone 12; it’s very fast, has a very nice screen, 5G, and great cameras, according to our review. It’s also available for preorder today on Apple’s website and will be widely available starting April 30th.
The 2021 iMac, new Apple TV 4K, and new iPad Pro models Apple showed off at the Spring Loaded event will be available for preorder starting April 30th.
(Pocket-lint) – Apple revealed the fifth generation iPad Pro 12.9 (2021) and third generation iPad Pro 11 (2021) at an event in April. The two devices sit above the fourth generation iPad Air (2020), the eighth generation iPad (2020) and the iPad mini.
You can read how all Apple’s iPad’s compare in our separate feature, but here we are looking at how the new iPad Pros compare to the iPad Air to help you work out which is right for you.
Here is how the iPad Pro 12.9 (2021) stacks up against the iPad Pro 11 (2021) and iPad Air (2020).
squirrel_widget_4537717
Design
iPad Pro 12.9 (2021): 280.6 x 214.9 x 6.4mm, 682g
iPad Pro 11 (2021): 247.6 x 178.5 x 5.9mm, 466g
iPad Air (2020): 247.6 x 178.5 x 6.1mm, 458g
The Apple iPad Pro 12.9 and Apple iPad Pro 11 share identical designs, though their measurements differ. The iPad Air meanwhile, borrows some of the iPad Pro’s design features, like very narrow bezels around the screen and an aluminium body with square edges but there are some differences elsewhere.
The iPad Pro models have a large square camera housing in the top left corner – like the iPhone 12 models – and they have two camera lenses within that housing. The iPad Air has a singular camera lens in the top left corner so there’s a slight step down in the camera department.
The iPad Pro models feature Face ID at the top of their displays, while the iPad Air has Touch ID built into the power button at the top – both allow for as much screen as possible in the body available though.
All models have a Smart Connector on the back and all are compatible with the second generation Apple Pencil and Magic Folio Keyboard.
The iPad Pro models have Thunderbolt/USB 4 for charging and data transfer, while the iPad Air has USB-C. The iPad Pro models come in Silver and Space Grey colours, but the iPad Air comes in Rose Gold, Green and Sky Blue on top of Silver and Space Grey, making for some more exciting finish options.
In terms of overall size and weight, the iPad Pro 12.9 (2021) is the largest and heaviest, while the iPad Pro 11 (2021) and iPad Air are almost identical in size and weight, with the iPad Pro 11 slightly slimmer and the iPad Air slightly lighter.
Display
iPad Pro 12.9 (2021): 12.9-inch, Liquid XDR, 2732 x 2048 resolution (264ppi), 1600nits, ProMotion, True Tone
iPad Pro 11 (2021): 11-inch, Liquid Retina, 2388 x 1668 resolution (264ppi), 600nits, ProMotion, True Tone
iPad Air (2020): 10.9-inch, Liquid Retina, 2360 x 1640 resolution (264ppi), 500nits, True Tone
The Apple iPad Pro 12.9 (2021) has a 12.9-inch Liquid Retina XDR display, which is the largest and brightest of the three iPads being compared here with a 1600nits peak brightness (HDR). The iPad Pro 11 (2021) and iPad Air have a Liquid Retina display, with the iPad Pro featuring an 11-inch screen and a max brightness of 600nits and the Air offering a 10.9-inch display with a max brightness of 500nits.
All three models have a pixel density of 264ppi and they all have an anti-reflective coating, P3 wide colour display, True Tone technology and a fully laminated display.
The iPad Pro models come with Apple’s ProMotion technology though, offering a 120Hz variable refresh rate, while the iPad Air doesn’t have this on board, marking the biggest distinction between the iPad Pro 11 and iPad Air in terms of display.
Hardware and specs
iPad Pro 12.9 (2021): Apple M1 chip, 8GB/16GB RAM, up to 2TB storage, 10-hour battery, 5G
iPad Pro 11 (2021): Apple M1 chip, 8GB/16GB RAM, up to 2TB storage, 10-hour battery, 5G
iPad Air (2020): A14 Bionic, up to 1TB storage, 10-hour battery, 4G
The Apple iPad Pro 12.9 (2021) and the iPad Pro 11 (2021) both run on Apple’s M1 chip – which is the same chip that can be found in the new iMac and the latest MacBook Pros so you’re talking about quite a bit of power here. They also both have come with a choice of 8GB or 16GB of RAM and storage options start at 128GB and go up to 2TB.
The 2021 iPad Pro models come in Wi-Fi only and Wi-Fi and Cellular options, with the latter offering 5G connectivity.
The iPad Air (2020) meanwhile, runs on the A14 Bionic chip which although still more than capable and a very powerful processor, isn’t quite as advanced as the M1. There are also no RAM options to choose between and storage only goes up to 1TB.
The iPad Air comes in Wi-Fi only and Wi-Fi and Cellular models too but the Wi-Fi and Cellular models are 4G rather than 5G.
All three models have a 10-hour battery life. As mentioned though, the iPad Pro models have Thunderbolt/USB 4, while the iPad Air has USB-C. The iPad Pro models also have four-speaker audio, while the iPad Air has two-speaker audio.
Cameras
iPad Pro 12.9 (2021): 12MP (f/1.8) +10MP (f/2.4) rear, 12MP front
iPad Pro 11 (2021): 12MP (f/1.8) +10MP (f/2.4) rear, 12MP front
iPad Air (2020): 12MP (f/1.8), 7MP front
Both the iPad Pro 12.9 (2021) and the iPad Pro 11 (2021) come with a 12-megapixel wide (f/1.8) and 10-megapixel ultra wide (f/2.4) camera on their rear. They also have 2x optical zoom out, 5x digital zoom and a brighter True Tone flash, as well as Smart HDR 3 for photos.
The iPad Air has a single 12-megapixel wide camera on the rear with an f/1.8 aperture. It offers 5x digital zoom and smart HDR 3 for photos.
On the front, the iPad Pro 12.9 and the iPad Pro 11 come with a 12-megapixel TrueDepth camera with ultra wide camera. It offers an f/2.4 aperture with 2x optical zoom out and a number of features including Centre Stage, portrait mode, Portrait Lighting, Animoji and Memoji and extended dynamic range for video up to 30fps.
The iPad Air meanwhile, has a 7-megapixel FaceTime HD camera with an f/2.2 aperture. It has a Retina Flash, Smart HDR 3 for photos and cinematic video stabilisation like the iPad Pro models, but it doesn’t have the other features mentioned above.
Price
iPad Pro 12.9 (2021): From £999
iPad Pro 11 (2021): From £749
iPad Air (2020): From £579
squirrel_widget_4537660
There’s quite a big difference in price between the iPad Pro models and the iPad Air.
The iPad Pro 12.9 starts at £999 in the UK for the Wi-Fi only model, and £1149 for the Wi-Fi and Cellular model. Opt for the top specs and you’re looking at quite a significant amount of money.
The iPad Pro 11 starts at £749 in the UK for the Wi-Fi only model and £899 for the Wi-Fi and Cellular model. Again, if you opt for the 2TB of storage and 16GB of RAM, you’re looking at serious bucks.
The iPad Air starts at £579 in the UK for the Wi-Fi only model, and £709 for the Wi-Fi and Cellular. You of course pay more for the larger storage models, but it is still significantly cheaper than the iPad Pro models.
squirrel_widget_2670462
Conclusion
The only difference between the iPad Pro 12.9 and the iPad Pro 11, apart from their physical sizes, is the display technology. The 12.9-inch model has an XDR display, while the 11-inch doesn’t. Otherwise their specs are the same, but you of course pay more for the larger model.
The iPad Pro 11 and iPad Air are the same size and they have pretty much the same display size too. The iPad Pro offers an extra camera on the rear, an improved front camera with features like Centre Stage, a more powerful processor, a higher storage option of 2TB, 5G capabilities, Thunderbolt over USB-C, RAM options and ProMotion on the display. The Air does have some more exciting colour options though, and it’s a bit lighter.
Which you choose of these models will likely come down to not only your budget but what features are important to you. The iPad Air (2020) is fantastic and will be more than adequate for many, though the iPad Pro models do obviously offer those extra premium features and speed.
The Samsung Z Flip 3 foldable smartphone will be greatly improved. With larger cover display, a 120Hz flexible screen, a triple camera and stereo speakers.
After the introduction of the Galaxy S21 series in mid-January this year, we now have to wait for the successor to the Galaxy Z Flip. This clamshell smartphone was announced simultaneously with the S20 series. The Galaxy Z Flip 3 is expected to be released in the summer of 2021. As time goes by, more and more details are known about the new folding phone from Samsung. In this publication, we take a closer look at the expected specifications and improvements over its predecessor.
To start with the name, it remains unknown for the time being under which name the successor to the Z Flip will be marketed. LetsGoDigital has recently learned from several sources that Samsung does not opt for the model name Galaxy Z Flip 2, but for Galaxy Z Flip 3. This is in line with previous rumors on the internet.
This allows the company to align the names of the Z Fold and Z Flip devices. The Galaxy Z Fold 3 is also expected in the second half of the year – both foldable phones will probably be announced simultaneously. The Z Flip 5G, which was introduced a few months after the 4G model, can then go down in history as the “Z Flip 2”.
Samsung Z Flip 3 foldable smartphone
Based on all the information already available about the Samsung Galaxy Z Flip 3, in-house graphic designer Giuseppe Spinelli, aka Snoreyn, has created a series of digital product images showing the possible design of Samsung’s new clamshell smartphone.
The most important changes from its predecessor are the larger cover display and the triple camera. The hinge will also be renewed and the bezels will be further reduced. Over time, several media have reported about these improvements, Samsung was also awarded a patent for such a Galaxy Z Flip design with triple camera at the end of 2020.
This patent does not stand alone, however, because recently – on March 11, 2021 – Samsung Electronics was awarded a patent for a “Foldable electronic device and control method therof”. It is a clamshell phone, comparable to the Galaxy Z Flip. This time, however, Samsung has integrated a significantly larger cover display. Giuseppe’s renders are based on this patent.
In addition, Samsung seems to want to pay extra attention to the thickness of the device. Making the device thinner improves portability. However, there is also a downside, because the frame becomes so narrow that operating the physical buttons also becomes more difficult, Samsung describes in the in-depth documentation. The South Korean manufacturer has come up with the following solution.
Samsung seems to want to significantly increase the touch-sensitive area around the buttons, making it easier to use the buttons – regardless of whether you’re using the phone open or closed.
The physical buttons are placed on one frame part. In the folded position, Samsung wants to enlarge the touch area exactly opposite the buttons, so that the user does not have to work very accurately during operation. Even in the unfolded position, this enlarged touch area remains usable – as illustrated in the image above.
The question remains whether this technology will already be applied to the Z Flip 3. Nevertheless, it is interesting to see what Samsung’s spearheads are for future folding models.
In any case, Samsung seems to intend to revise the smartphone frame. Last week, LetsGoDigital discovered that Samsung has registered a trademark for the name ‘Armor Frame‘, which seems to indicate that the Z Flip 3 and / or the Z Fold 3 will feature a renewed and sturdier frame – which may also be thinner and lighter.
This does not seem to be the only point on which Samsung wants to improve sustainability. SamMobile recently announced that Samsung will provide its upcoming foldable smartphones with an IP rating for the first time. In other words, the Z Flip 3 is likely to be dust and water resistant. It is still unknown whether it is an IP68 rating. The folding devices may not be completely waterproof, but only splash-proof. Last year, Samsung was already awarded a patent for a waterproof Galaxy Fold.
Larger cover display, new hinge and smaller bezels
There is still some uncertainty about the size of the cover screen. Many hope for a screen size similar to that of the Motorola Razr – as Samsung has also patented several times. However, according to the latest information, the cover display is becoming significantly smaller than hoped and expected. It would be a 1.83-inch display.
“The Z Flip 2 will have a 6.7-inch main display and a 1.83-inch cover display,” display analyst Ross Young reported on Twitter earlier this month. Shortly before, Chun reported on the same social media platform that the new Z Flip will feature a 1.9″ cover display and a 6.8″ main screen.
Although the cover screen appears to be significantly larger than the current 1.1 ”display, a 1.83” display is still quite limited. For comparison, the Motorola Razr features a 2.7-inch front display. You can undoubtedly use the cover screen to see the time, answer calls and view incoming notifications. For other things you will probably be forced to open the device, after which a 6.7-inch screen unfolds.
The 6.7” format corresponds in size to the flexible screen of the current Z Flip. Nevertheless, Samsung seems to make some changes to the main screen. Some time ago Ice Universe reported via Weibo that the refresh rate will be increased to 120 Hertz. This is also the case with the Galaxy Z Fold 2, which makes it very likely that this information is correct.
Samsung also intends to reduce the bezels. In addition, the new model would be marketed more cheaply. However, no price indication was issued – we will get back to this later.
Rumors have been circulating for some time that Samsung will also renew the hinge. Based on the design of the current Flip, this also seems to be necessary to be able to reduce the bezels, and thus to align the design more with regular smartphone models in 2021. Perhaps the renewed hinge will also make it possible to close the device completely – without a gap, where dust and dirt can accumulate.
Samsung will probably also make the hinge available in different colors. For example, with the Z Fold 2 you can choose from four color variants: silver, gold, blue and red. These special editions are only available via Samsung’s website. For the time being, this personalization option is not available for the Z Flip, but it is in line with expectations that Samsung will also make additional color variants available for the Z Flip 3 exclusively through its website.
Speaking of colors, the Samsung Z Flip 3 is expected to be released in four colors at launch: black, beige, green and violet purple. These are the colors that we have reflected in the product renders. The beige and green variant are completely new, the black and purple colorways are also available for the original Z Flip – presumably Samsung will add a little twist to this and link it to a new name. In addition, the Galaxy Z Fold 3 is expected to appear in the same new colors: beige and green – besides a black variant.
Hardware & Software
Naturally, Samsung will also install a new chipset. The Qualcomm Snapdragon 888 chipset will probably be placed under the hood. Presumably two memory variants will be made available this time: 128GB and 256GB.
Its predecessor was only available with 256GB of memory. By also offering a 128GB variant, Samsung can lower the entry-level price to make the foldable smartphone accessible to a wider audience. Samsung is expected to release both a Galaxy Z Flip 3 5G and 4G model.
Naturally, the new Galaxy Z-series smartphone will run on the Android operating system. Android 11, in combination with the One UI 3.5 interface. This is an updated user interface compared to the One UI 3.1, with which the S21 series debuted.
Renewed camera
Much remains unclear about the camera. Various patents have shown that Samsung is considering implementing a triple camera. Thus, the camera system would also be more in line with that of regular smartphones. The Z Flip has a 12 megapixel wide angle and a 12 megapixel ultra wide angle camera. A telephoto zoom camera may be added.
In addition, an extra camera is available when you use the device in open position. Handy for taking selfies or making a video call. The punch-hole camera will most likely also be retained in the new model. Presumably the same 10 megapixel image sensor is used – which is also used in the S21 / S21 +. As an alternative, Samsung could also opt for a dual punch-hole camera – the manufacturer recently filed a patent for this.
Another point Samsung is likely to improve is audio quality. The Samsung Z Flip 3 will probably be equipped with a stereo speaker, which would be a good step forward. Its predecessor was equipped with a single speaker – which is very minimal for a high-end phone. It seems that this is about to change with the new generation.
Battery and charging options
With regard to the battery, last year Samsung opted for a dual battery with a total capacity of 3,300 mAh. Two recent certifications from Safety Korea and Dekra Certification have shown that the Z Flip 3 also comes with two batteries, with the total battery capacity remaining unchanged. It concerns a 2,300 mAh battery (EB-BF711ABY) and a smaller 903 mAh battery (EB-BF712ABY).
It is expected that the larger battery will be placed in the bottom half of the device, the smaller battery will be integrated in the top part to drive the cover display. Many hoped that Samsung would increase the battery capacity, as the battery performance of the Z Flip was rated as “poor” in many expert reviews. However, increasing the battery capacity would also contribute to making the device thicker, it seems that Samsung is simply not willing to make this concession.
Regarding the charging options, just like its predecessor, the Z Flip 3 is expected to be able to be charged wired and wirelessly. Reverse wireless charging will also be supported. The smartphone can probably be charged faster than its predecessor, with a max. charging power of 25W – instead of 15W. Wireless charging will likely be supported up to 15W.
Price & Availability
Samsung will most likely host a Galaxy Unpacked event in July. During that event the Z Flip 3 5G will be introduced – one year after the introduction of the Z Flip 5G. Pre-order will likely start directly after the event. The clamshell phone will then be released approx. two weeks later, on a Friday.
There are increasing signs that the Z Fold 3 will be announced simultaneously with the Galaxy Z Flip 3. Around the same period, the Galaxy S21 FE is also expected, as the cheapest member of the S21 line-up. Unfortunately a Galaxy Note 21 is no longer expected this year.
With the Galaxy Z Flip, Samsung is targeting a different audience than with the Z Fold. The prices of both folding devices also differ considerably. Samsung is expected to maintain this differentiation. The Z Flip will remain the cheap model, meant for those who want a compact device. While the Z Fold is aimed at people who want to work extra productively, on an extra large screen.
While the Z Flip 3 will feature the same powerful chipset and latest software as the Z Fold 3, Samsung will most likely make concessions in terms of camera, memory and battery.
Last year, the Galaxy Z Flip got a suggested retail price of € 1500. The Z Flip 5G, introduced a few months later, went on sale for the same price. Although it is still unclear what the Z Flip 3 will cost exactly, several sources have indicated that the new model will be marketed more cheaply than its predecessor. This may result in a starting price of approx € 1350 – This would close the gap between regular and foldable smartphones. However, there is one more possibility …
Samsung Galaxy Z Flip 3 Lite
In the meantime, the thought has arisen on the internet that Samsung is working on an extra cheap model. A kind of “Galaxy Z Flip 3 Lite”, which may be marketed as “Galaxy Z Flip 3 FE”.
However, it remains unknown whether this device will be introduced at the same time. Details about this model are still very scarce, which suggests that this model will not be released until a later date. Perhaps the chip shortage, caused by the corona crisis, is the cause of this.
Initially, it was thought that a Galaxy Z Fold 3 Lite is also in development, but this model seems to have been canceled. Instead, Samsung first wants to release a cheap version of the Z Flip. The clamshell is of course about € 500 cheaper than the Z Fold variant. By releasing a Lite model of this device, Samsung can make the foldable smartphone accessible to a wider audience. Moreover, the competition is not standing still either…
Alternative choices for Samsung foldable smartphones
Last year, the Motorola Razr was the main competitor of the Z Flip. However, more and more Chinese manufacturers are now also preparing for the introduction of one or more foldable phones.
Earlier this year, the Huawei Mate X2 was announced for the Chinese market, last month the Xiaomi Mi Mix Fold was also released. Both are competitors to the Z Fold. In all likelihood, Oppo and Vivo will soon be added to the list.
Chances are that it will not stay with one model, Xiaomi seems to want to release three foldable models this year, including a clamshell phone. A clamshell model is also expected from Oppo this year.
All in all, Samsung cannot afford to sit back, the South Korean manufacturer is in the lead and will certainly try to maintain this position in the future. Therefore, we are already looking forward to the Galaxy Unpacked 2021 Summer event!
Here you can take a look at the patent documentation of the Samsung Z Flip including additional images.
Note to editors :The product images in this publication are created by in-house graphic designer Giuseppe Spinelli (aka Snoreyn). The presented concept renders are for illustrative purposes only. The images are copyright protected. Feel free to use the pictures on your own website, please be so respectful to include a source link into your publication.
We use cookies on our website to give you the most relevant experience. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.