The U.S. Commerce Department has added seven Chinese entities to the DoC’s Entity List, essentially barring these companies and organizations from obtaining almost all advanced technologies developed in the U.S. Among the entities are two major CPU developers from China: Tianjin Phytium Information Technology and Sunway Microelectronics (or Shenwei Microelectronics).
The Department of Commerce’s Bureau of Industry and Security (BIS) believes that the newly added seven entities supported modernization of the Chinese People Liberation Army by producing supercomputers used for military purposes, development of new weapons of mass destruction as well as other destabilizing efforts. In particular, BIS blacklisted four supercomputer sites in China, including the National Supercomputing Center Jinan, the National Supercomputing Center Shenzhen, the National Supercomputing Center Wuxi, and the National Supercomputing Center Zhengzhou.
Also, the blacklist now includes CPU designer Tianjin Phytium Information Technology, which develops system-on-chips for client and server PCs based on the Armv8 ISA, and Sunway Microelectronics, which as a part of Shanghai High-Performance Integrated Circuit Design Center, designs proprietary supercomputer processors.
The inclusion of an entity into the Entity List restricts its ability to access items and technologies that are parts of the U.S. Export Administration Regulations (EAR). American companies cannot export, re-export, or transfer items subject to the EAR to entities in the Entity List without a special license, which will be subject to a presumption of denial.
CPUs and SoCs, including those for supercomputers, are designed using electronic design automation (EDA) as well as other tools and technologies developed in the U.S. Without access to these tools and technologies, it will be close to impossible for Phytium or Sunway to develop their processors. It is unclear whether contract makers of semiconductor like TSMC or SMIC can actually produce chips for Phytium and Sunway.
“I have not in my decade in China met a chip design company that isn’t using either Synopsys or Cadence,” said Stewart Randall, a consultant in Shanghai who sells electronic design automation software to top Chinese chipmakers in a conversation with The Washington Post.
Many supercomputer centers in China nowadays use CPUs and SoCs developed in the country, but they still use certain technologies designed in the U.S. From now on, those who want to sell the aforementioned four supercomputer centers in China something made or developed in the U.S. will have to apply for an appropriate license.
“Supercomputing capabilities are vital for the development of many – perhaps almost all – modern weapons and national security systems, such as nuclear weapons and hypersonic weapons,” said U.S. Secretary of Commerce Gina M. Raimondo in a statement. “The Department of Commerce will use the full extent of its authorities to prevent China from leveraging U.S. technologies to support these destabilizing military modernization efforts.”
Previously the DoC blacklisted Huawei Technologies and its chip design arm HiSilicon as well as contract maker of chips SMIC on the same grounds of supporting Chinese military efforts.
According to a tweet by leaker @momomo_us, Intel is refreshing its Xeon D lineup with the Ice Lake architecture. These parts are known as Ice Lake-D and will be replacing older Xeon D architectures with several major upgrades.
Xeon D is a branch of Xeon processors aimed towards the ‘microserver’ market, these chips are optimized for ultra-low power consumption while maintaining decent performance. These chips are categorized between the Atom and Xeon E3 families of CPUs and designed for low-end server workloads. Xeon D competes directly with ARM server processors from competing chip fabs.
Image 1 of 2
(Image credit: Twitter)
Image 2 of 2
(Image credit: Twitter)
The biggest upgrade coming to Ice Lake-D is memory support, current Xeon D processors are limited to 512GB on the higher core count variants, while the lower core count models are limited to just 128GB of memory. This might sound like a lot of RAM, but in the server space, 128GB-512GB of memory can be quite limiting depending on the workload.
Ice Lake-D upgrades the memory capacity for higher core count variants to 1TB of memory capacity, as well as 2933MT/s memory speeds (up from 2667MT/s). We don’t know how much memory capacity the lower core count Ice Lake-D CPUs will have, but according to an ASRock board layout for these chips, they will be limited to triple channel memory support like the last generation. So expect RAM capacity to be below 1TB.
Image 1 of 2
(Image credit: Twitter)
Image 2 of 2
(Image credit: Twitter)
For core counts, Ice Lake-D will be upgraded to a maximum of 20 cores on the top-end models, compared to just 16 for the current-gen chips. Plus these new CPUs will be built on the modern Ice Lake 10nm process, so expect a nice jump in efficiency with the new architecture.
TDPs remain the same, with configurations ranging from 25W to 110W.
The biggest mystery remaining for Ice Lake-D is its actual performance and performance per watt, we’ll have to wait until later this year for Intel to share details on the actual performance of these processors.
A leaked slide purported to be from Intel’s roadmap summarizes what we know about Intel’s upcoming 4th Generation Xeon Scalable ‘Sapphire Rapids’ processor, with some additional details. (Thanks, VideoCardz.)
Intel has always envisioned its Sapphire Rapids processor and the Eagle Stream platform as a revolutionary product. Paired with Intel’s Xe-HPC ‘Ponte Vecchio’ compute GPU, Sapphire Rapids will power Intel’s first exascale supercomputer that will rely on an AI+HPC paradigm. In the datacenter, the new CPU will have to support a host of new technologies that are not yet available, as datacenter workloads are changing. Sapphire Rapids radically differs from its predecessors on multiple levels, including microarchitecture, memory hierarchy, platform, and even design ideology.
The Sapphire Rapids CPU
The Sapphire Rapids CPU will adopt a multi-chip module design (or rather a multi-chiplet module) featuring four identical chips located next to each other and packed using Intel’s EMIB technology. Each chip contains 14 Golden Cove cores, the same cores used for the Alder Lake CPUs. However, these cores will feature numerous datacenter/supercomputer enhancements when compared to their desktop counterparts.
In particular, Sapphire Rapids will support Advanced Matrix Extensions (AMX); AVX512_BF16 extension for deep learning; Intel’s Data Streaming Accelerator (DSA), a data copy and transformation accelerator that offloads appropriate assignments from CPU cores (NVMe calls are rather expensive); architectural LBRs (last branch recording); and HLAT (a hypervisor-managed linear address translation). The maximum number of cores supported by Sapphire Rapids will be 56, but there will naturally be models with 44, 28, or even 24 cores.
As far as memory is concerned, Sapphire Rapids will support HBM2E, DDR5, and Intel’s Optane Persistent Memory 300-series (codenamed Crow Pass) non-volatile DIMMs. At least some Sapphire Rapids CPU SKUs will carry up to 64GB of HBM2E DRAM, offering 1TB/s of bandwidth per socket. We don’t know whether these will be separate HBM2E packages placed next to CPU chiplets, or if they’ll be stacked below them using Intel’s Foveros packaging technology.
The processor will also feature eight DDR5-4800 memory channels supporting one module per channel (thus offering 307.2 GB/s of bandwidth per socket). Today, 1DPC sounds like a limitation, but even using Samsung’s recently announced 512GB RDIMM modules eight channels will bring 4TB of memory, and higher capacity DDR5 modules will be available later.
Finally, Sapphire Rapids processors can be paired with Intel’s Optane Persistent Memory 300-series 3DXPoint-based modules, which are said to increase bandwidth substantially compared to existing offerings. Optane modules are meant to bring a lot of relatively cheap memory closer to the CPU to accelerate applications like in-memory databases, so many of Intel’s partners would like to have these modules. However, considering the fact that it’s unclear which company will produce 3D XPoint for Intel starting in 2022 (as Micron is pulling away from 3D XPoint production and abandons the project), we have no idea whether such modules will be launched at all. Theoretically, Intel could validate JEDEC-standard upcoming NVDIMMs with its next-generation CPUs, but this is speculation.
Intel’s Sapphire Rapids processors will be made using the company’s 10nm Enhanced SuperFin technology that’s optimized for performance. With all the advantages that the new CPUs will bring, they will be rather power hungry. The information says that their maximum TDP will hit 350W (up from 270W in case of the Ice Lake-SP), so there’s a question on what sort of cooling they’ll require. Meanwhile, Intel’s upcoming LGA4677 socket will probably be able to deliver a huge amount of power to the CPU.
The Eagle Stream Platform
Being aimed at a wide variety of workloads, Intel’s Eagle Stream platform will support one, two, four, and eight LGA4677 sockets. Cooling will be an interesting topic to discuss in regards to high-performance Sapphire Rapids SKUs for HPC applications, which sometimes use eight CPUs per machine. Meanwhile, these CPUs will use Intel’s UPI 2.0 interface that will deliver up to 16 GT/s data transfer rates, up from 11.2 GT/s today. Each CPU will have up to four UPI 2.0 links (probably external links).
As far as other enhancements are concerned, Intel’s Sapphire Rapids processor will support up to 80 PCIe 5.0 lanes (with x16, x8, x4 bifurcation) at 32 GT/s, and a PCIe 4.0 x2 link. On top of PCIe Gen5, the CPUs will support the CXL 1.1 protocol to optimize CPU-to-device (for accelerators) as well as CPU-to-memory (for memory expansion and storage devices) communications.
Some Grains of Salt
Intel started sampling of its 4th Generation Xeon Scalable ‘Sapphire Rapids’ processors several months ago, so it’s not surprising that a number of their previously unknown features and capabilities (e.g., HBM2E support and MCM design) were revealed by various unofficial sources in the recent months. In fact, we expect more interesting leaks as more server makers gain access to the new CPUs.
Unfortunately, the leaks were never confirmed by Intel or excerpts from its leaked documents, so it’s possible some of the information is incorrect. The slide from an alleged Intel roadmap confirms many of Sapphire Rapids’ capabilities that are (or were) at least planned to be supported, but keep in mind that these are not the final specifications of Intel’s products that will ship in 2022.
At this point we cannot confirm legitimacy of the slide, though we can confirm that a substantial portion of information revealed by the paper is indeed correct and has been either confirmed by Intel, or our sources with knowledge of the matter. Meanwhile, we have no idea how old the slide is, so take it with a grain of salt.
A Google Fi user in Hawaii received a couple text messages Monday night wishing him a happy Easter. The problem is, those messages had been sent on Easter Sunday, but only made it through more than a day later.
Google is now informing Fi users who receive text messages through Hangouts that messages sent to them may have gone missing between March 31st and April 5th. The company said there was a service “interruption” that impacted “a small number of people.” Google says it has now resolved the issue and is sending through the delayed messages. Missing messages should appear in Hangouts by the end of today, April 7th.
Fi users have for years been able to send and receive calls and messages through Hangouts, but Google announced plans years ago to strip those features out as it transitioned Hangouts into yet another Google communications app. The features appear to have been disabled within the last week.
But the interruption occurred before the service was fully shut down, and so Google is still working to patch the delayed messages through to Hangouts. A Google spokesperson confirmed the service interruption to The Verge and said affected users are being contacted. SMS messages will be delivered to Messages by Google or another default messaging app going forward.
Delayed messages can cause real problems for senders and receivers. In November 2019, more than 168,000 messages were delivered that had originally been sent on Valentine’s Day 2019, nine months earlier. People received confusing, context-free messages — in some cases, messages came through from people who had died in the months between. The issue was caused by a server failure at Syniverse, a firm that routes text messages between carriers.
Google has been in the process of shutting down Hangouts for years, so it’s possible there weren’t many users left using the service in conjunction with Fi. Even the Fi user in Hawaii — who, full disclosure, is a friend of mine — said they knew they should have switched a while ago and decided not to.
“I intentionally put myself in this spot,” Jason Bennett, who received the delayed Easter messages, told The Verge. “I wanted to see what happened when it went offline.”
The body of an email sent to Fi users whose messages were delayed.
It probably won’t make the list of best CPU coolers for end users anytime soon, but Microsoft’s data center servers could be getting a massive thermal management upgrade in the near future. Right now, the software giant is testing a radical new cooling technology known as boiling liquid, which promises to be higher performance, more reliable, and cheaper to maintain compared to traditional air cooling systems in data centers right now.
Servers that are equipped with this new prototype cooling system look very similar to mineral oil PCs if you’ve seen one. Dozens of server blades are packed tightly together in a fully submerged tank of boiling liquid. The liquid of course is non-conductive so the servers can operate safely inside the liquid environment.
The liquid is a special unknown recipe that boils at 122 degrees Fahrenheit (which is 90 degrees lower than the boiling point of water). The low boiling point is needed to drive heat away from critical components. Once the liquid begins boiling, it’ll automatically roll up to the surface, allowing cooled condensers to contact the liquid, returning the cooling liquid to its fully liquidized state.
Effectively, this system is one gigantic vapor chamber. Both cooling systems rely on chemical reactions to bring heat from system components to cooling chambers, whether that be heatsinks or, in this case, a condenser.
(Image credit: Microsoft)
Death of Moore’s Law Is to Blame
Microsoft’s says that it is developing such a radically new cooling technology is because of the rising demands of power and heat from computer components, which are only going to get worse.
The software giant claims that the death of Moore’s Law is to blame for this; transistors on computer chips have become so small that they’ve hit the atomic level. Soon you won’t be able to shrink the transistors on a new process node any smaller as it will be physically impossible to do so.
To counter this, chip fabs have had to increase power consumption quite significantly to keep increasing CPU performance — namely from adding more and more cores to a CPU.
Microsoft notes that CPUs have increased from 150 watts to more than 300 watts per chip, and GPUs have increased to more than 700 watts per chip on average. Bear in mind that Microsoft is talking about server components and not about consumer desktops where the best CPUs and best graphics cards tend to have less power consumption than that.
If server components get more and more power-hungry, Microsoft believes this new liquid solution will be necessary to keep costs down on server infrastructure.
Boiling Liquid Is Optimized For Low Maintenance
Microsoft took inspiration from the datacenter server clusters operating on seabeds when developing the new cooling technology.
A few years ago Microsoft unleashed Project Natick, which was a massive operation to bring datacenters underwater to inherit the benefits of using seawater as a cooling system.
To do this, the server chambers were filled with dry nitrogen air instead of oxygen and use cooling fans, a heat exchanger, and a specialized plumbing system that pipes in seawater through the cooling system.
What Microsoft learned was the sheer reliability of water/liquid cooling. The servers on the seafloor experienced one-eighth the failure rate of replica servers on land with traditional air cooling.
Analysis of the situation indicates the lack of humidity and corrosive effects of oxygen were responsible for the increased sustainability of these servers.
Microsoft hopes its boiling liquid technology will have the same effects. If so, we could see a revolution in the data center world where servers are smaller, and much more reliable. Plus with this new cooling system, server performance is hopefully increased as well.
Perhaps the boosting algorithms we see on Intel and AMD’s desktop platforms can be adopted into the server world so processors can automatically hit higher clocks when they detect more thermal headroom.
(Pocket-lint) – If you were to pick out a gaming genre that’s hard to break into right now, online looter-shooters would be high up on the list. High-profile attempts like Anthem have shown how difficult it can be to upset the hierarchy.
That’s just what developer People Can Fly is trying to do with Outriders. And to its credit there’s clearly a solid foundation here. It’s built a looter-shooter that feels punchy and rewarding, with an endgame that has promising depth as it stands.
A survival story
Outrider’s framing story is refreshingly straightforward and intelligible. Escaping from a dying earth, your colony ship reaches its destination, a lush new planet called Enoch. However, all isn’t well and, after a scouting expedition on the surface goes awry, you wake up to find that decades have passed.
Enoch hasn’t been the welcoming paradise that was promised, and is instead home to a bizarre anomaly that’s altering the planet and its animals to fight back against the invasion of humans. The world you wake up to is war-torn and fractured, with factions battling over resources and a scarce few mutants gifted extraodinary powers by the anomaly, yourself included.
Best upcoming Xbox One games to look forward to this year
Best upcoming PS5 games: The top PlayStation titles to anticipate
It’s hokey stuff at times, but anyone who’s tried to understand just what on earth is going on in the Destiny universe will appreciate that simplicity can be a good thing.
People Can Fly previously made the raucous shooter Bulletstorm, so some of that game’s brash humour can be traced through to Outriders – but it sadly doesn’t always land. Your player character is, straightforwardly, a bit of a misanthrope. That attitude can make for pithy lines, but it can also mean a baffling lack of empathy and/or sympathy for non-playable characters (NPCs) that you’re supposed to care about.
People Can Fly
With acres of extra lore added into your codex at all times, there’s plenty of world-building to dig into here if you like, but keeping things simple in broader story terms is a welcome choice, in short. That said, Outriders could do without so many interrupting cut-scenes, given the hitch in loading that these seem to entail at present.
Class warfare
The core of the Outriders value proposition, though, isn’t really in how it delivers its side quests. It’s in how it feels to play, and this is an area where you can feel People Can Fly’s experience shining through.
Given the studio also worked on Gears of War Judgement, it’s no surprise that this is a third-person cover shooter that feels polished and fluid. After the game’s prologue, which you can later skip to create new characters quickly, you choose one of four classes.
People Can Fly
Pyromancers have flaming abilities that mark enemies for death; Technomancers can create turrets and heal allies; Devastators can tank loads of damage and hold areas more easily; and our personal favourite, Tricksters, can zip around the battlefield slicing and dicing foes.
There’s no swapping between classes other than by changing characters entirely, but running more than one character is very straightforward and well worth trying. This will help you get to grips with which you most enjoy, and each path offers up multiple skills to choose from to tweak your loadout.
Then you’ve got the actual guns, which are multitudinous and offer increasingly enjoyable modifiers as you progress. Things start off grounded but pretty soon you’ll be freezing enemies with bullets, or shooting an SMG that has explosive rounds, or any number of other variables.
These can be relatively easily mixed-and-matched using the in-depth crafting system, too, letting you find your favourite mods and keep them in your arsenal. One miss at the moment is the lack of transmogrification, a big word that basically means letting you keep exotic weapon skins while changing what they do, but it’s reasonable to hope that might come with time.
For now, guns and powers come together to make for a cover shooter than can also be plenty mobile and reactive, and kinetic when you find a power-set that agrees with you. That said, if you’re playing alone, we’d recommend you opt for the Trickster for your first character. Some of the other paths are a little harder to manage early on without backup keeping you healthy.
People Can Fly
There are periodically large bosses to contend with, which do a decent job of offering a different sort of battle, at scale, even if they can tend to be slightly bullet-spongey in practise. These fights still give a climactic feel to key moments.
It’s also up to you to decide what level of difficulty you want to set your game world at, with rewards corresponding to how far you can push yourself. This is another smart choice that lets you easily strap in for a more chilled session if you want to kick back with some friends, or make it tough as nails if you’re in it for top-tier loot.
Playing in solo mode is plenty fun and fairly well-balanced, but the game is really aimed at trios, where three players can pick loadouts that complement each other and dominate the chest-high cover battlefields that most fights take place in. Played like this, Outriders can be frantic good fun.
Smooth in patches
As with many cross-generation releases, the visual side of things is a mixed bag for Outriders, which largely depends on your platform. Playing on PlayStation 5, we had nice quick load times and the whole game plays at a smooth 60fps with only very rare stutters, just as it should on Xbox Series X and S.
On older-generation consoles the game runs at 30fps, something that’s hardly new for those platforms but still feels signficantly more sluggish when you try it. However, there’s no difference in what you can do and how you do it – it’s purely a visual disparity, also reflected by lower resolutions.
People Can Fly
In art direction terms, though, Outriders posts solid results without much to write home about. Enoch might be a raw alien world but the spaces it offers up to fight in, at present, aren’t the most visually ravishing you’ve ever seen.
Its encampments and forts are straight out of Gears of War, as are the chunky oversized weapons and, while you’ll fight across different biomes, none of them are all that fresh. You’ll see ice levels, forested areas, built-up ruins and lava-strewn wastelands, and it’s all serviceable without being memorable.
That’s not helped by the fact that every arena will inevitably need to feature the age-old maze of chest-high walls to fight around, something that really hamstrings any attempt to make levels feel really naturalistic.
Enemy design is also pretty ho-hum, with a whole bunch of burly blokes in armour sets charging at you for most of the game’s span, interrupted by occasional beasties.
People Can Fly
Still, the particle effects that your powers summon up look vibrant and jazz things up, and running on next-gen hardware the game can look great in big battles, especially when you’re in the more colourful locations.
As an always-online title, though, Outriders launched with some technical issues that were disappointing to say the least. With player numbers presumably inflated by its late-notice inclusion on Xbox Game Pass, server outages have been frequent since release, although the situation is improving all the time. Launch problems are nothing new for online titles, but that doesn’t make them acceptable, especially for those who paid full price for a game they couldn’t access.
Top PS4 games 2021: Best PlayStation 4 and PS4 Pro games every gamer must own
By Rik Henderson
·
Verdict
As it stands (and assuming the servers straighten out after the launch troubles), Outriders is a good bit of fun for anyone who’s into third-person shooters or light role-players.
In a time when co-op experiences are thin on the ground it offers up a lengthy campaign you can play through with a couple of friends, and there’s a bombastic, if simplistic, time to be had while doing so.
With a loot and crafting system that can potentially offer up real depth for those who want something to sink into, there’s also plenty of promise in the endgame here, even before you unlock expeditions that offer up high-tier loot for the most dedicated players.
The fact that it’s a complete package is also a tonic compared to a full live-service offering, although whether it’s enough to keep people playing much beyond the campaign will remain to be seen.
Writing by Max Freeman-Mills. Editing by Mike Lowe.
Intel’s long-delayed 10nm+ third-gen Xeon Scalable Ice Lake processors mark an important step forward for the company as it attempts to fend off intense competition from AMD’s 7nm EPYC Milan processors that top out at 64 cores, a key advantage over Intel’s existing 14nm Cascade Lake Refresh that tops out at 28 cores. The 40-core Xeon Platinum 8380 serves as the flagship model of Intel’s revamped lineup, which the company says features up to a 20% IPC uplift on the strength of the new Sunny Cove core architecture paired with the 10nm+ process.
Intel has already shipped over 200,000 units to its largest customers since the beginning of the year, but today marks the official public debut of its newest lineup of data center processors, so we get to share benchmarks. The Ice Lake chips drop into dual-socket Whitley server platforms, while the previously-announced Cooper Lake slots in for quad- and octo-socket servers. Intel has slashed Xeon pricing up to 60% to remain competitive with EPYC Rome, and with EPYC Milan now shipping, the company has reduced per-core pricing again with Ice Lake to remain competitive as it targets high-growth markets, like the cloud, enterprise, HPC, 5G, and the edge.
The new Xeon Scalable lineup comes with plenty of improvements, like increased support for up to eight memory channels that run at a peak of DDR4-3200 with two DIMMs per channel, a notable improvement over Cascade Lake’s support for six channels at DDR4-2933 and matching EPYC’s eight channels of memory. Ice Lake also supports 6TB of DRAM/Optane per socket (4TB of DRAM) and 4TB of Optane Persistent Memory DIMMs per socket (8 TB in dual-socket). Unlike Intel’s past practices, Ice Lake also supports the full memory and Optane capacity on all models with no additional upcharge.
Intel has also moved forward from 48 lanes of PCIe 3.0 connectivity to 64 lanes of PCIe 4.0 (128 lanes in dual-socket), improving both I/O bandwidth and increasing connectivity to match AMD’s 128 available lanes in a dual-socket server.
Intel says that these additives, coupled with a range of new SoC-level optimizations, a focus on improved power management, along with support for new instructions, yield an average of 46% more performance in a wide range of data center workloads. Intel also claims a 50% uplift to latency-sensitive applications, like HammerDB, Java, MySQL, and WordPress, and up to 57% more performance in heavily-threaded workloads, like NAMD, signaling that the company could return to a competitive footing in what has become one of AMD’s strongholds — heavily threaded workloads. We’ll put that to the test shortly. First, let’s take a closer look at the lineup.
Intel Third-Gen Xeon Scalable Ice Lake Pricing and Specfications
We have quite the list of chips below, but we’ve actually filtered out the downstream Intel parts, focusing instead on the high-end ‘per-core scalable’ models. All told, the Ice Lake family spans 42 SKUs, with many of the lower-TDP (and thus performance) models falling into the ‘scalable performance’ category.
Intel also has specialized SKUs targeted at maximum SGX enclave capacity, cloud-optimized for VMs, liquid-cooled, networking/NFV, media, long-life and thermal-friendly, and single-socket optimized parts, all of which you can find in the slide a bit further below.
Cores / Threads
Base / Boost – All Core (GHz)
L3 Cache (MB)
TDP (W)
1K Unit Price / RCP
EPYC Milan 7763
64 / 128
2.45 / 3.5
256
280
$7,890
EPYC Rome 7742
64 / 128
2.25 / 3.4
256
225
$6,950
EPYC Milan 7663
56 / 112
2.0 / 3.5
256
240
$6,366
EPYC Milan 7643
48 / 96
2.3 / 3.6
256
225
$4.995
Xeon Platinum 8380
40 / 80
2.3 / 3.2 – 3.0
60
270
$8,099
Xeon Platinum 8368
38 / 76
2.4 / 3.4 – 3.2
57
270
$6,302
Xeon Platinum 8360Y
36 / 72
2.4 / 3.5 – 3.1
54
250
$4,702
Xeon Platinum 8362
32 / 64
2.8 / 3.6 – 3.5
48
265
$5,448
EPYC Milan 7F53
32 / 64
2.95 / 4.0
256
280
$4,860
EPYC Milan 7453
28 / 56
2.75 / 3.45
64
225
$1,570
Xeon Gold 6348
28 / 56
2.6 / 3.5 – 3.4
42
235
$3,072
Xeon Platinum 8280
28 / 56
2.7 / 4.0 – 3.3
38.5
205
$10,009
Xeon Gold 6258R
28 / 56
2.7 / 4.0 – 3.3
38.5
205
$3,651
EPYC Milan 74F3
24 / 48
3.2 / 4.0
256
240
$2,900
Intel Xeon Gold 6342
24 / 48
2.8 / 3.5 – 3.3
36
230
$2,529
Xeon Gold 6248R
24 / 48
3.0 / 4.0
35.75
205
$2,700
EPYC Milan 7443
24 / 48
2.85 / 4.0
128
200
$2,010
Xeon Gold 6354
18 / 36
3.0 / 3.6 – 3.6
39
205
$2,445
EPYC Milan 73F3
16 / 32
3.5 / 4.0
256
240
$3,521
Xeon Gold 6346
16 / 32
3.1 / 3.6 – 3.6
36
205
$2,300
Xeon Gold 6246R
16 / 32
3.4 / 4.1
35.75
205
$3,286
EPYC Milan 7343
16 / 32
3.2 / 3.9
128
190
$1,565
Xeon Gold 5317
12 / 24
3.0 / 3.6 – 3.4
18
150
$950
Xeon Gold 6334
8 / 16
3.6 / 3.7 – 3.6
18
165
$2,214
EPYC Milan 72F3
8 / 16
3.7 / 4.1
256
180
$2,468
Xeon Gold 6250
8 / 16
3.9 / 4.5
35.75
185
$3,400
At 40 cores, the Xeon Platinum 8380 reaches new heights over its predecessors that topped out at 28 cores, striking higher in AMD’s Milan stack. The 8380 comes at $202 per core, which is well above the $130-per-core price tag on the previous-gen flagship, the 28-core Xeon 6258R. However, it’s far less expensive than the $357-per-core pricing of the Xeon 8280, which had a $10,008 price tag before AMD’s EPYC upset Intel’s pricing model and forced drastic price reductions.
With peak clock speeds of 3.2 GHz, the 8380 has a much lower peak clock rate than the previous-gen 28-core 6258R’s 4.0 GHz. Even dipping down to the new 28-core Ice Lake 6348 only finds peak clock speeds of 3.5 GHz, which still trails the Cascade Lake-era models. Intel obviously hopes to offset those reduced clock speeds with other refinements, like increased IPC and better power and thermal management.
On that note, Ice Lake tops out at 3.7 GHz on a single core, and you’ll have to step down to the eight-core model to access these clock rates. In contrast, Intel’s previous-gen eight-core 6250 had the highest clock rate, 4.5 GHz, of the Cascade Lake stack.
Surprisingly, AMD’s EPYC Milan models actually have higher peak frequencies than the Ice Lake chips at any given core count, but remember, AMD’s frequencies are only guaranteed on one physical core. In contrast, Intel specs its chips to deliver peak clock rates on any core. Both approaches have their merits, but AMD’s more refined boost tech paired with the 7nm TSMC process could pay dividends for lightly-threaded work. Conversely, Intel does have solid all-core clock rates that peak at 3.6 GHz, whereas AMD has more of a sliding scale that varies based on the workload, making it hard to suss out the winners by just examining the spec sheet.
Ice Lake’s TDPs stretch from 85W up to 270W. Surprisingly, despite the lowered base and boost clocks, Ice Lake’s TDPs have increased gen-on-gen for the 18-, 24- and 28-core models. Intel is obviously pushing higher on the TDP envelope to extract the most performance out of the socket possible, but it does have lower-power chip options available (listed in the graphic below).
AMD has a notable hole in its Milan stack at both the 12- and 18-core mark, a gap that Intel has filled with its Gold 5317 and 6354, respectively. Milan still holds the top of the hierarchy with 48-, 56- and 64-core models.
Image 1 of 12
(Image credit: Intel)
Image 2 of 12
(Image credit: Intel)
Image 3 of 12
(Image credit: Intel)
Image 4 of 12
(Image credit: Intel)
Image 5 of 12
(Image credit: Intel)
Image 6 of 12
(Image credit: Intel)
Image 7 of 12
(Image credit: Intel)
Image 8 of 12
(Image credit: Intel)
Image 9 of 12
(Image credit: Intel)
Image 10 of 12
(Image credit: Intel)
Image 11 of 12
(Image credit: Intel)
Image 12 of 12
(Image credit: Intel)
The Ice Lake Xeon chips drop into Whitley server platforms with Socket LGA4189-4/5. The FC-LGA14 package measures 77.5mm x 56.5mm and has an LGA interface with 4189 pins. The die itself is predicted to measure ~600mm2, though Intel no longer shares details about die sizes or transistor counts. In dual-socket servers, the chips communicate with each other via three UPI links that operate at 11.2 GT/s, an increase from 10.4 GT/s with Cascade Lake. . The processor interfaces with the C620A chipset via four DMI 3.0 links, meaning it communicates at roughly PCIe 3.0 speeds.
The C620A chipset also doesn’t support PCIe 4.0; instead, it supports up to 20 lanes of PCIe 3.0, ten USB 3.0, and fourteen USB 2.0 ports, along with 14 ports of SATA 6 Gbps connectivity. Naturally, that’s offset by the 64 PCIe 4.0 lanes that come directly from the processor. As before, Intel offers versions of the chipset with its QuickAssist Technology (QAT), which boosts performance in cryptography and compression/decompression workloads.
Image 1 of 12
(Image credit: Intel)
Image 2 of 12
(Image credit: Intel)
Image 3 of 12
(Image credit: Intel)
Image 4 of 12
(Image credit: Intel)
Image 5 of 12
(Image credit: Intel)
Image 6 of 12
(Image credit: Intel)
Image 7 of 12
(Image credit: Intel)
Image 8 of 12
(Image credit: Intel)
Image 9 of 12
(Image credit: Intel)
Image 10 of 12
(Image credit: Intel)
Image 11 of 12
(Image credit: Intel)
Image 12 of 12
(Image credit: Intel)
Intel’s focus on its platform adjacencies business is a key part of its messaging around the Ice Lake launch — the company wants to drive home its message that coupling its processors with its own differentiated platform additives can expose additional benefits for Whitley server platforms.
The company introduced new PCIe 4.0 solutions, including the new 200 GbE Ethernet 800 Series adaptors that sport a PCIe 4.0 x16 connection and support RDMA iWARP and RoCEv2, and the Intel Optane SSD P5800X, a PCIe 4.0 SSD that uses ultra-fast 3D XPoint media to deliver stunning performance results compared to typical NAND-based storage solutions.
Intel also touts its PCIe 4.0 SSD D5-P5316, which uses the company’s 144-Layer QLC NAND for read-intensive workloads. These SSDs offer up to 7GBps of throughput and come in capacities stretching up to 15.36 TB in the U.2 form factor, and 30.72 TB in the E1.L ‘Ruler’ form factor.
Intel’s Optane Persistent Memory 200-series offers memory-addressable persistent memory in a DIMM form factor. This tech can radically boost memory capacity up to 4TB per socket in exchange for higher latencies that can be offset through software optimizations, thus yielding more performance in workloads that are sensitive to memory capacity.
The “Barlow Pass” Optane Persistent Memory 200 series DIMMs promise 30% more memory bandwidth than the previous-gen Apache Pass models. Capacity remains at a maximum of 512GB per DIMM with 128GB and 256GB available, and memory speeds remain at a maximum of DDR4-2666.
Intel has also expanded its portfolio of Market Ready and Select Solutions offerings, which are pre-configured servers for various workloads that are available in over 500 designs from Intel’s partners. These simple-to-deploy servers are designed for edge, network, and enterprise environments, but Intel has also seen uptake with cloud service providers like AWS, which uses these solutions for its ParallelCluster HPC service.
Image 1 of 10
(Image credit: Intel)
Image 2 of 10
(Image credit: Intel)
Image 3 of 10
(Image credit: Intel)
Image 4 of 10
(Image credit: Intel)
Image 5 of 10
(Image credit: Intel)
Image 6 of 10
(Image credit: Intel)
Image 7 of 10
(Image credit: Intel)
Image 8 of 10
(Image credit: Intel)
Image 9 of 10
(Image credit: Intel)
Image 10 of 10
(Image credit: Intel)
Like the benchmarks you’ll see in this review, the majority of performance measurements focus on raw throughput. However, in real-world environments, a combination of throughput and responsiveness is key to deliver on latency-sensitive SLAs, particularly in multi-tenant cloud environments. Factors such as loaded latency (i.e., the amount of performance delivered to any number of applications when all cores have varying load levels) are key to ensuring performance consistency across multiple users. Ensuring consistency is especially challenging with diverse workloads running on separate cores in multi-tenant environments.
Intel says it focused on performance consistency in these types of environments through a host of compute, I/O, and memory optimizations. The cores, naturally, benefit from increased IPC, new ISA instructions, and scaling up to higher core counts via the density advantages of 10nm, but Intel also beefed up its I/O subsystem to 64 lanes of PCIe 4.0, which improves both connectivity (up from 48 lanes) and throughput (up from PCIe 3.0).
Intel says it designed the caches, memory, and I/O, not to mention power levels, to deliver consistent performance during high utilization. As seen in slide 30, the company claims these alterations result in improved application performance and latency consistency by reducing long tail latencies to improve worst-case performance metrics, particularly for memory-bound and multi-tenant workloads.
Image 1 of 12
(Image credit: Intel)
Image 2 of 12
(Image credit: Intel)
Image 3 of 12
(Image credit: Intel)
Image 4 of 12
(Image credit: Intel)
Image 5 of 12
(Image credit: Intel)
Image 6 of 12
(Image credit: Intel)
Image 7 of 12
(Image credit: Intel)
Image 8 of 12
(Image credit: Intel)
Image 9 of 12
(Image credit: Intel)
Image 10 of 12
(Image credit: Intel)
Image 11 of 12
(Image credit: Intel)
Image 12 of 12
(Image credit: Intel)
Ice Lake brings a big realignment of the company’s die that provides cache, memory, and throughput advances. The coherent mesh interconnect returns with a similar arrangement of horizontal and vertical rings present on the Cascade Lake-SP lineup, but with a realignment of the various elements, like cores, UPI connections, and the eight DDR4 memory channels that are now split into four dual-channel controllers. Here we can see that Intel shuffled around the cores on the 28-core die and now has two execution cores on the bottom of the die clustered with I/O controllers (some I/O is now also at the bottom of the die).
Intel redesigned the chip to support two new sideband fabrics, one controlling power management and the other used for general-purpose management traffic. These provide telemetry data and control to the various IP blocks, like execution cores, memory controllers, and PCIe/UPI controllers.
The die includes a separate peer-to-peer (P2P) fabric to improve bandwidth between cores, and the I/O subsystem was also virtualized, which Intel says offers up to three times the fabric bandwidth compared to Cascade Lake. Intel also split one of the UPI blocks into two, creating a total of three UPI links, all with fine-grained power control of the UPI links. Now, courtesy of dedicated PLLs, all three UPIs can modulate clock frequencies independently based on load.
Densely packed AVX instructions augment performance in properly-tuned workloads at the expense of higher power consumption and thermal load. Intel’s Cascade Lake CPUs drop to lower frequencies (~600 to 900 MHz) during AVX-, AVX2-, and AVX-512-optimized workloads, which has hindered broader adoption of AVX code.
To reduce the impact, Intel has recharacterized its AVX power limits, thus yielding (unspecified) higher frequencies for AVX-512 and AVX-256 operations. This is done in an adaptive manner based on three different power levels for varying instruction types. This nearly eliminates the frequency delta between AVX and SSE for 256-heavy and 512-light operations, while 512-heavy operations have also seen significant uplift. All Ice Lake SKUs come with dual 512b FMAs, so this optimization will pay off across the entire stack.
Intel also added support for a host of new instructions to boost cryptography performance, like VPMADD52, GFNI, SHA-NI, Vector AES, and Vector Carry-Less multiply instructions, and a few new instructions to boost compression/decompression performance. All rely heavily upon AVX acceleration. The chips also support Intel’s Total Memory Encryption (TME) that offers DRAM encryption through AES-XTS 128-bit hardware-generated keys.
Intel also made plenty of impressive steps forward on the microarchitecture, with improvements to every level of the pipeline allowing Ice Lake’s 10nm Sunny Cove cores to deliver far higher IPC than 14nm Cascade Lake’s Skylake-derivative architecture. Key improvements to the front end include larger reorder, load, and store buffers, along with larger reservation stations. Intel increased the L1 data cache from 32 KiB, the capacity it has used in its chips for a decade, to 42 KiB, and moved from 8-way to 12-way associativity. The L2 cache moves from 4-way to 8-way and is also larger, but the capacity is dependent upon each specific type of product — for Ice Lake server chips, it weighs in at 1.25 MB per core.
Intel expanded the micro-op cache (UOP) from 1.5K to 2.25K micro-ops, the second-level translation lookaside buffer (TLB) from 1536 entries to 2048, and moved from a four-wide allocation to five-wide to allow the in-order portion of the pipeline (front end) to feed the out-of-order (back end) portion faster. Additionally, Intel expanded the Out of Order (OoO) Window from 224 to 352. Intel also increased the number of execution units to handle ten operations per cycle (up from eight with Skylake) and focused on improving branch prediction accuracy and reducing latency under load conditions.
The store unit can now process two store data operations for every cycle (up from one), and the address generation units (AGU) also handle two loads and two stores each cycle. These improvements are necessary to match the increased bandwidth from the larger L1 data cache, which does two reads and two writes every cycle. Intel also tweaked the design of the sub-blocks in the execution units to enable data shuffles within the registers.
Intel also added support for its Software Guard Extensions (SGX) feature that debuted with the Xeon E lineup, and increased capacity to 1TB (maximum capacity varies by model). SGX creates secure enclaves in an encrypted portion of the memory that is exclusive to the code running in the enclave – no other process can access this area of memory.
Test Setup
We have a glaring hole in our test pool: Unfortunately, we do not have AMD’s recently-launched EPYC Milan processors available for this round of benchmarking, though we are working on securing samples and will add competitive benchmarks when available.
We do have test results for the AMD’s frequency-optimized Rome 7Fx2 processors, which represent AMD’s performance with its previous-gen chips. As such, we should view this round of tests largely through the prism of Intel’s gen-on-gen Xeon performance improvement, and not as a measure of the current state of play in the server chip market.
We use the Xeon Platinum Gold 8280 as a stand-in for the less expensive Xeon Gold 6258R. These two chips are identical and provide the same level of performance, with the difference boiling down to the more expensive 8280 coming with support for quad-socket servers, while the Xeon Gold 6258R tops out at dual-socket support.
Image 1 of 7
(Image credit: Tom’s Hardware)
Image 2 of 7
(Image credit: Tom’s Hardware)
Image 3 of 7
(Image credit: Tom’s Hardware)
Image 4 of 7
(Image credit: Tom’s Hardware)
Image 5 of 7
(Image credit: Tom’s Hardware)
Image 6 of 7
(Image credit: Tom’s Hardware)
Image 7 of 7
(Image credit: Tom’s Hardware)
Intel provided us with a 2U Server System S2W3SIL4Q Software Development Platform with the Coyote Pass server board for our testing. This system is designed primarily for validation purposes, so it doesn’t have too many noteworthy features. The system is heavily optimized for airflow, with the eight 2.5″ storage bays flanked by large empty bays that allow for plenty of air intake.
The system comes armed with dual redundant 2100W power supplies, a 7.68TB Intel SSD P5510, an 800GB Optane SSD P5800X, and an E810-CQDA2 200GbE NIC. We used the Intel SSD P5510 for our benchmarks and cranked up the fans for maximum performance in our benchmarks.
We tested with the pre-installed 16x 32GB DDR4-3200 DIMMs, but Intel also provided sixteen 128GB Optane Persistent Memory DIMMs for further testing. Due to time constraints, we haven’t yet had time to test the Optane DIMMs, but stay tuned for a few demo workloads in a future article. As we’re not entirely done with our testing, we don’t want to risk prying the 8380 out of the socket yet for pictures — the large sockets from both vendors are becoming more finicky after multiple chip reinstalls.
Memory
Tested Processors
Intel S2W3SIL4Q
16x 32GB SK hynix ECC DDR4-3200
Intel Xeon Platinum 8380
Supermicro AS-1023US-TR4
16x 32GB Samsung ECC DDR4-3200
EPYC 7742, 7F72, 7F52
Dell/EMC PowerEdge R460
12x 32GB SK hynix DDR4-2933
Intel Xeon 8280, 6258R, 5220R, 6226R
To assess performance with a range of different potential configurations, we used a Supermicro 1024US-TR4 server with three different EPYC Rome configurations. We outfitted this server with 16x 32GB Samsung ECC DDR4-3200 memory modules, ensuring the chips had all eight memory channels populated.
We used a Dell/EMC PowerEdge R460 server to test the Xeon processors in our test group. We equipped this server with 12x 32GB Sk hynix DDR4-2933 modules, again ensuring that each Xeon chip’s six memory channels were populated.
We used the Phoronix Test Suite for benchmarking. This automated test suite simplifies running complex benchmarks in the Linux environment. The test suite is maintained by Phoronix, and it installs all needed dependencies and the test library includes 450 benchmarks and 100 test suites (and counting). Phoronix also maintains openbenchmarking.org, which is an online repository for uploading test results into a centralized database.
We used Ubuntu 20.04 LTS to maintain compatibility with our existing test results, and leverage the default Phoronix test configurations with the GCC compiler for all tests below. We also tested all platforms with all available security mitigations.
Naturally, newer Linux kernels, software, and targeted optimizations can yield improvements for any of the tested processors, so take these results as generally indicative of performance in compute-intensive workloads, but not as representative of highly-tuned deployments.
Linux Kernel, GCC and LLVM Compilation Benchmarks
Image 1 of 2
(Image credit: Tom’s Hardware)
Image 2 of 2
(Image credit: Tom’s Hardware)
AMD’s EPYC Rome processors took the lead over the Cascade Lake Xeon chips at any given core count in these benchmarks, but here we can see that the 40-core Ice Lake Xeon 8380 has tremendous potential for these type of workloads. The dual 8380 processors complete the Linux compile benchmark, which builds the Linux kernel at default settings, in 20 seconds, edging out the 64-core EPYC Rome 7742 by one second. Naturally, we expect AMD’s Milan flagship, the 7763, to take the lead in this benchmark. Still, the implication is clear — Ice Lake-SP has significantly-improved performance, thus reducing the delta between Xeon and competing chips.
We can also see a marked improvement in the LLVM compile, with the 8380 reducing the time to completion by ~20% over the prior-gen 8280.
Molecular Dynamics and Parallel Compute Benchmarks
Image 1 of 6
(Image credit: Tom’s Hardware)
Image 2 of 6
(Image credit: Tom’s Hardware)
Image 3 of 6
(Image credit: Tom’s Hardware)
Image 4 of 6
(Image credit: Tom’s Hardware)
Image 5 of 6
(Image credit: Tom’s Hardware)
Image 6 of 6
(Image credit: Tom’s Hardware)
NAMD is a parallel molecular dynamics code designed to scale well with additional compute resources; it scales up to 500,000 cores and is one of the premier benchmarks used to quantify performance with simulation code. The Xeon 8380’s notch a 32% improvement in this benchmark, slightly beating the Rome chips.
Stockfish is a chess engine designed for the utmost in scalability across increased core counts — it can scale up to 512 threads. Here we can see that this massively parallel code scales well with EPYC’s leading core counts. The EPYC Rome 7742 retains its leading position at the top of the chart, but the 8380 offers more than twice the performance of the previous-gen Cascade Lake flagship.
We see similarly impressive performance uplifts in other molecular dynamics workloads, like the Gromacs water benchmark that simulates Newtonian equations of motion with hundreds of millions of particles. Here Intel’s dual 8380’s take the lead over the EPYC Rome 7742 while pushing out nearly twice the performance of the 28-core 8280.
We see a similarly impressive generational improvement in the LAAMPS molecular dynamics workload, too. Again, AMD’s Milan will likely be faster than the 7742 in this workload, so it isn’t a given that the 8380 has taken the definitive lead over AMD’s current-gen chips, though it has tremendously improved Intel’s competitive positioning.
The NAS Parallel Benchmarks (NPB) suite characterizes Computational Fluid Dynamics (CFD) applications, and NASA designed it to measure performance from smaller CFD applications up to “embarrassingly parallel” operations. The BT.C test measures Block Tri-Diagonal solver performance, while the LU.C test measures performance with a lower-upper Gauss-Seidel solver. The EPYC Milan 7742 still dominates in this workload, showing that Ice Lake’s broad spate of generational improvements still doesn’t allow Intel to take the lead in all workloads.
Rendering Benchmarks
Image 1 of 4
(Image credit: Tom’s Hardware)
Image 2 of 4
(Image credit: Tom’s Hardware)
Image 3 of 4
(Image credit: Tom’s Hardware)
Image 4 of 4
(Image credit: Tom’s Hardware)
Turning to more standard fare, provided you can keep the cores fed with data, most modern rendering applications also take full advantage of the compute resources. Given the well-known strengths of EPYC’s core-heavy approach, it isn’t surprising to see the 64-core EPYC 7742 processors retain the lead in the C-Ray benchmark, and that applies to most of the Blender benchmarks, too.
Encoding Benchmarks
Image 1 of 3
(Image credit: Tom’s Hardware)
Image 2 of 3
(Image credit: Tom’s Hardware)
Image 3 of 3
(Image credit: Tom’s Hardware)
Encoders tend to present a different type of challenge: As we can see with the VP9 libvpx benchmark, they often don’t scale well with increased core counts. Instead, they often benefit from per-core performance and other factors, like cache capacity. AMD’s frequency-optimized 7F52 retains its leading position in this benchmark, but Ice Lake again reduces the performance delta.
Newer software encoders, like the Intel-Netflix designed SVT-AV1, are designed to leverage multi-threading more fully to extract faster performance for live encoding/transcoding video applications. EPYC Rome’s increased core counts paired with its strong per-core performance beat Cascade Lake in this benchmark handily, but the step up to forty 10nm+ cores propels Ice Lake to the top of the charts.
Compression, Security and Python Benchmarks
Image 1 of 5
(Image credit: Tom’s Hardware)
Image 2 of 5
(Image credit: Tom’s Hardware)
Image 3 of 5
(Image credit: Tom’s Hardware)
Image 4 of 5
(Image credit: Tom’s Hardware)
Image 5 of 5
(Image credit: Tom’s Hardware)
The Pybench and Numpy benchmarks are used as a general litmus test of Python performance, and as we can see, these tests typically don’t scale linearly with increased core counts, instead prizing per-core performance. Despite its somewhat surprisingly low clock rates, the 8380 takes the win in the Pybench benchmark and improves Xeon’s standing in Numpy as it takes a close second to the 7F52.
Compression workloads also come in many flavors. The 7-Zip (p7zip) benchmark exposes the heights of theoretical compression performance because it runs directly from main memory, allowing both memory throughput and core counts to heavily impact performance. As we can see, this benefits the core-heavy chips as they easily dispatch with the chips with lesser core counts. The Xeon 8380 takes the lead in this test, but other independent benchmarks show that AMD’s EPYC Milan would lead this chart.
In contrast, the gzip benchmark, which compresses two copies of the Linux 4.13 kernel source tree, responds well to speedy clock rates, giving the 16-core 7F52 the lead. Here we see that 8380 is slightly slower than the previous-gen 8280, which is likely at least partially attributable to the 8380’s much lower clock rate.
The open-source OpenSSL toolkit uses SSL and TLS protocols to measure RSA 4096-bit performance. As we can see, this test favors the EPYC processors due to its parallelized nature, but the 8380 has again made big strides on the strength of its higher core count. Offloading this type of workload to dedicated accelerators is becoming more common, and Intel also offers its QAT acceleration built into chipsets for environments with heavy requirements.
Conclusion
Admittedly, due to our lack of EPYC Milan samples, our testing today of the Xeon Platinum 8380 is more of a demonstration of Intel’s gen-on-gen performance improvements rather than a holistic view of the current competitive landscape. We’re working to secure a dual-socket Milan server and will update when one lands in our lab.
Overall, Intel’s third-gen Xeon Scalable is a solid step forward for the Xeon franchise. AMD has steadily chewed away data center market share from Intel on the strength of its EPYC processors that have traditionally beaten Intel’s flagships by massive margins in heavily-threaded workloads. As our testing, and testing from other outlets shows, Ice Lake drastically reduces the massive performance deltas between the Xeon and EPYC families, particularly in heavily threaded workloads, placing Intel on a more competitive footing as it faces an unprecedented challenge from AMD.
AMD will still hold the absolute performance crown in some workloads with Milan, but despite EPYC Rome’s commanding lead in the past, progress hasn’t been as swift as some projected. Much of that boils down to the staunchly risk-averse customers in the enterprise and data center; these customers prize a mix of factors beyond the standard measuring stick of performance and price-to-performance ratios, instead focusing on areas like compatibility, security, supply predictability, reliability, serviceability, engineering support, and deeply-integrated OEM-validated platforms.
AMD has improved drastically in these areas and now has a full roster of systems available from OEMs, along with broadening uptake with CSPs and hyperscalers. However, Intel benefits from its incumbency and all the advantages that entails, like wide software optimization capabilities and platform adjacencies like networking, FPGAs, and Optane memory.
Although Ice Lake doesn’t lead in all metrics, it does improve the company’s positioning as it moves forward toward the launch of its Sapphire Rapids processors that are slated to arrive later this year to challenge AMD’s core-heavy models. Intel still holds the advantage in several criteria that appeal to the broader enterprise market, like pre-configured Select Solutions and engineering support. That, coupled with drastic price reductions, has allowed Intel to reduce the impact of a fiercely-competitive adversary. We can expect the company to redouble those efforts as Ice Lake rolls out to the more general server market.
ServeTheHome has just confirmed that Lenovo is fully utilizing AMD’s Platform Secure Boot (or PSB) in its server and workstation pre-built machines. This feature locks AMD’s Ryzen Pro, Threadripper Pro, and EPYC processors out from being used in other systems in an effort to reduce CPU theft.
More specifically, this feature effectively cancels out a CPU’s ability to be used in another motherboard, or at least a motherboard not from the original OEM. If a thief wanted to steal these chips, they would have to hack the PSB hardware and firmware to get the chip functioning in other hardware.
But that would be super difficult to do. AMD’s Platform Secure Boot runs on a 32-bit AMD secure ARM SoC with its own operating system. The hardware isolation is another layer of security for the system, as it’s nearly impossible to access FSB since the system won’t be able to detect the ARM processor in the main operating system.
In theory, this feature is an excellent idea. It effectively makes these chips OEM exclusive, which can help reduce CPU theft. On the other hand, this feature will prevent current owners of these pre-builts from using the chips in other systems down the road.
It’s not much of a problem today, but suppose the system gets a CPU upgrade in the future. The old CPU effectively becomes e-waste, unless it ends up in the hands of someone who already has a compatible Lenovo system. Alternatively, if a motherboard fails, it locks the user into using a replacement motherboard from the original vendor.
Thankfully, this feature has to be enabled by an OEM in the first place, so you can still go out and buy an EPYC, Ryzen Pro, or Threadripper Pro CPU/system that isn’t using this feature specifically. Still, this feature can be a double edged sword. Most people buying servers aren’t going to be swapping chips out and using them in other systems, so this potential issue should be quite rare.
Perhaps more worrisome is that Ryzen Pro processors from the Renoir and Cezanne families also support PSB. Enabling it on that sort of hardware and the resulting vendor lock-in would limit the ability to part out such PCs in the future.
Microsoft is starting to submerge its servers in liquid to improve their performance and energy efficiency. A rack of servers is now being used for production loads in what looks like a liquid bath. This immersion process has existed in the industry for a few years now, but Microsoft claims it’s “the first cloud provider that is running two-phase immersion cooling in a production environment.”
The cooling works by completely submerging server racks in a specially designed non-conductive fluid. The fluorocarbon-based liquid works by removing heat as it directly hits components and the fluid reaches a lower boiling point (122 degrees Fahrenheit or 50 degrees Celsius) to condense and fall back into the bath as a raining liquid. This creates a closed-loop cooling system, reducing costs as no energy is needed to move the liquid around the tank, and no chiller is needed for the condenser either.
Boiling liquid surrounds servers at a Microsoft data center.Image: Microsoft
“It’s essentially a bath tub,” explains Christian Belady, vice president of Microsoft’s data center advanced development group, in an interview with The Verge. “The rack will lie down inside that bath tub, and what you’ll see is boiling just like you’d see boiling in your pot. The boiling in your pot is at 100 degrees Celsius, and in this case it’s at 50 degrees Celsius.”
This type of liquid cooling has been used by cryptominers in recent years to mine for bitcoin and other cryptocurrencies. This method inspired Microsoft to trial its use over the last few years, using it to test against spikes of cloud demand and intensive workloads for applications like machine learning.
Most data centers are air cooled right now, using outside air and cooling it by dropping it to temperatures below 35 degrees Celsius using evaporation. This is known as swamp cooling, but it uses a lot of water in the process. This new liquid bath technique is designed to reduce water usage. “It potentially will eliminate the need for water consumption in data centers, so that’s a really important thing for us,” says Belady. “It’s really all about driving less and lower impact for wherever we land.”
Microsoft is hoping to see less hardware failures.Image: Microsoft
This tub of servers also allows Microsoft to more tightly pack hardware together, which should reduce the amount of space needed in the long term compared to traditional air cooling. Microsoft is trialing this initially with a small internal production workload, with plans to use it more broadly in the future. “It’s in a small data center, and we’re looking at one rack’s worth,” says Belady. “We have a whole phased approach, and our next phase is pretty soon with multiple racks.”
Microsoft is going to be mainly studying the reliability implications of this new cooling and what types of burst workloads it could even help with for cloud and AI demand. “We expect much better reliability. Our work with the Project Natick program a few years back really demonstrated the important of eliminating humidity and oxygen from an environment,” explains Belady.
Microsoft’s special container for its liquid bath servers.Image: Microsoft
Project Natick saw Microsoft sink an entire data center to the bottom of the Scottish sea, plunging 864 servers and 27.6 petabytes of storage into the water. The experiment was a success, and Microsoft had just one-eighth the failure rate of a land-based data center. “What we’re expecting with immersion is a similar trend, because the fluid displaces the oxygen and the humidity, and both of those create corrosion … and those are the things that create failure in our systems,” says Belady.
Part of this work is also related to Microsoft’s environmental pledge to tackle water scarcity. The company has committed to replenish even more water than it uses for its global operations by 2030. This includes Microsoft using an on-site rainwater collection system at its offices and collecting condensation from air conditioners to water plants. Nevertheless, Microsoft withdrew nearly 8 million cubic meters of water from municipal systems and other local sources in 2019, compared to a little over 7 million in 2018.
Microsoft’s effort to address its water usage will be extremely challenging given its trend toward more water usage, but projects like two-phase immersion will certainly help if it’s rolled out more broadly. “Our goal is to get to zero water usage,” says Belady. “That’s our metric, so that’s what we’re working towards.”
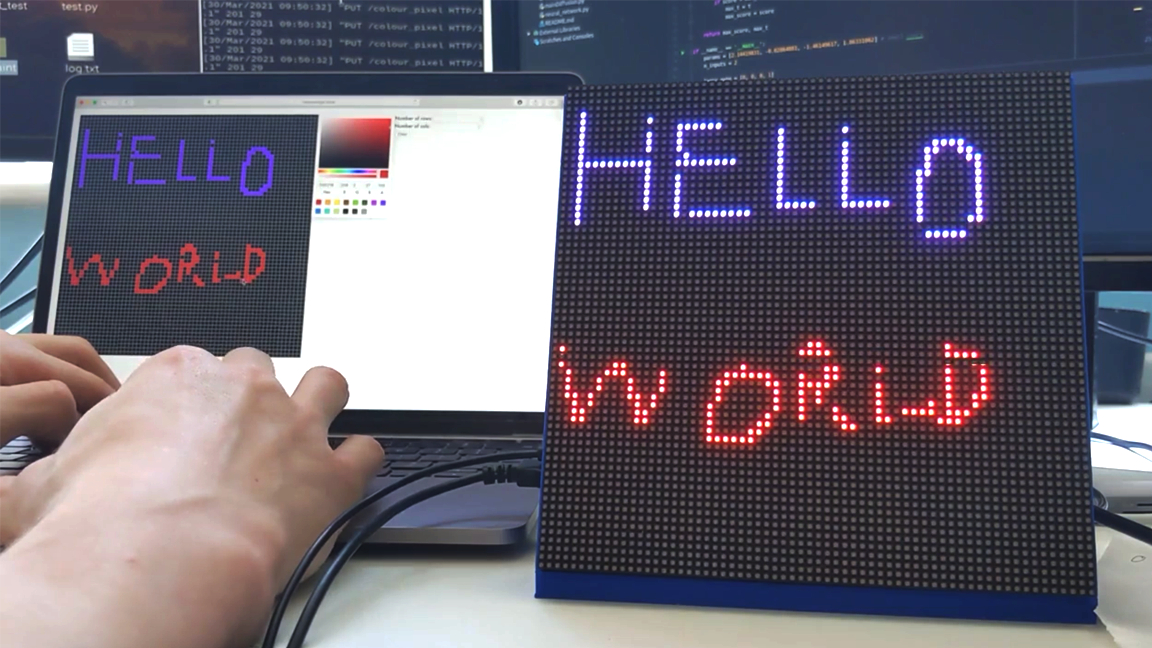
Customizing a matrix with a Raspberry Pi can be tricky, but Neythen Treloar’s project changes that by making it possible to paint an image onto a matrix in real-time from any browser. This isn’t the first time we’ve shared Neythen’s work, we previously showcased his matrix-based video game project.
The new project is dubbed Pixel Paint and it’s completely open-source for the community to use—the best Raspberry Pi projects usually are.
The code for this application was written using three languages: Javascript, C++ and Python. A Django backend server is used to operate the web app and bridge the communication between the matrix LEDs and browser input.
According to Neythen, the project was tested and proved to work with a Raspberry Pi 4, Raspberry 3 A and even a Pi Zero (albeit with some latency). There are plans in the works to upgrade the project with text input support.
In the meantime, you can check out the source code on GitHub and read more about this project in detail on the original thread from Reddit.
Many Microsoft services, including Microsoft Teams and Xbox Live, are experiencing outages for some users as of Thursday evening.
Microsoft’s Office 365 status page says there is a “DNS issue affecting multiple Microsoft 365 and Azure services.” The page also says that Microsoft has “rerouted traffic to our resilient DNS capabilities and are seeing improvement in service availability.” The company says the DNS issue has affected Microsoft Teams the most, though “other Microsoft 365 and Azure services may be affected.” The Microsoft 365 status account first acknowledged that there was an issue at 5:45PM ET.
Microsoft rerouted traffic to our resilient DNS capabilities and are seeing improvement in service availability. We are continuing to investigate the cause of the DNS issue. The next update will be provided in 60 minutes or as events warrant.
— Microsoft 365 Status (@MSFT365Status) April 1, 2021
The Xbox status page says that many services have a “major outage,” including accounts, multiplayer, and cloud gaming. Microsoft’s @XboxSupport account said “any issues you may see with Party Chat, Matchmaking or Sign-in on your Xbox consoles is [sic] currently under investigation” at 6:55PM ET. The account has also retweeted recent posts from the Outriders Twitter account about server issues.
Any issues you may see with Party Chat, Matchmaking or Sign-in on your Xbox consoles is currently under investigation. We’ll post updates here and at https://t.co/PzAdjUFMJj
— Xbox Support (@XboxSupport) April 1, 2021
Microsoft didn’t immediately reply to a request for comment.
This isn’t the only recent Microsoft services outage. Microsoft Teams, Azure, and other Microsoft 365 services went down for about four hours on March 15th.
Update April 1st, 7:09PM ET: Added new tweet from Microsoft.
As Intel’s Xeon Scalable ‘Ice Lake-SP’ processors are getting closer to formal launch, more information about their specifications appears to have leaked. This time around, famous leaker @momomo_us published a list of Ice Lake-SP CPUs with general specifications along with their prices in Southern Europe.
As it turns out, one of Intel’s partners from Portugal or Spain has either started to take orders on Intel’s upcoming 3rd-Generation Xeon Scalable processors codenamed Ice Lake-SP, or just included them in its price list.
Since the CPUs have not been announced by Intel, it is impossible to verify accuracy of their specifications, but at least their model numbers as well as general specifications corroborate with those published by Hewlett Packard Enterprise a couple of weeks ago.
The leaked list of Intel’s Ice Lake-SP processors for servers includes 18 Xeon Platinum and Xeon Gold processors with 16, 18, 28, 32, 36, 38 or 40 cores. As reported, the Xeon Platinum 8380 will feature 40 cores clocked at 2.30 GHz and will, be equipped with 60 MB of LLC (1.5 MB per core). The model 8380 will be among Intel’s highest-performing chips for datacenters and will be priced accordingly: chip is projected to cost €8,411 ($9,875) without VAT (21%).
(Image credit: @momomo_us)
Meanwhile there will also be numerous Xeon Platinum models with 38 and 36 cores that will sit below the higher end model, but will operate at higher clocks and will cost significantly less than the 40-core SKU.
Typically, Intel’s families of server CPUs are much broader, so expect the Ice Lake-SP lineup to contain more products aimed at machines that need less than 28 cores per socket or support more memory per socket.
Discord is the latest company to introduce a Clubhouse-like feature that lets people easily broadcast live audio conversations to a room of virtual listeners. Discord says its take, called Stage Channels, is available now on all platforms where Discord is available, including Windows, macOS, Linux, iOS, Android, and the web.
If you’ve used Discord before, you might know that the app already offers voice channels, which typically allow everyone in them to talk freely. A Stage Channel, on the other hand, is designed to only let certain people talk at once to a group of listeners, which could make them useful for more structured events like community town halls or AMAs. However, only Community servers, which have some more powerful community management tools than a server you might share with a few of your buddies, can make the new Stage Channels.
The feature’s broad availability makes Discord the first app to offer an easy way to host or listen in on social audio rooms on most platforms. Clubhouse is still only available on iOS, though an Android version is in development. Twitter’s Spaces feature works on iOS and Android, but only some users have the ability to make audio rooms right now. (The company plans to let anyone host a Space starting in April.) LinkedIn, Mark Cuban, Slack, and Spotify are also working on live audio features, and Facebook reportedly has one in the works, too.
At the top of this post, you can see what a Discord Stage Channel looks like on desktop, and here’s what one looks like on mobile:
Image: Discord
I got to participate in a Stage Channel to be briefed on the feature, and it was quite similar to using Clubhouse or Twitter Spaces. When I joined the Stage Channel, I was automatically put on mute and listed as an audience member. I could see who was speaking and who else was with me in the virtual crowd.
When I wanted to ask questions, I pressed a button to request to speak, and a Stage moderator brought me “on stage” so I could talk. Stage moderators can also mute speakers or even remove them from the room if they are being disruptive.
TrendForce predicted that DRAM prices would rise 13-18% in the second quarter of 2021, DigiTimes reports, as suppliers maintain bit output despite steady demand.
The research firm claimed that PC DRAM buyers have enough inventory to last them four to five weeks, per the report, and that manufacturers are buying as much DRAM as they can now so they won’t have to purchase it at a higher price later in the year.
DRAM suppliers have reportedly maintained production levels in the face of this increasing (or at least consistent) demand from their customers. By now everyone can do the math: increased demand plus limited supply equals higher prices.
TrendForce reportedly said DRAM suppliers also have increased demand from the server market, where it predicted a 20% price increase in 2Q21. There’s increased demand from the smartphone market, too, but the server market gets priority.
DigiTimes reported that all of these factors could lead to price increases for 8GB DDR4 modules of 15% or more in the second quarter, per its industry sources.
TrendForce’s report is the latest indication that manufacturers will have to worry more about DRAM pricing as well as the broader chip shortage limiting the supply of CPUs, GPUs, and all the devices that rely upon them. (To say nothing of NAND woes.)
These estimates also seem to assume something akin to “business as usual,” but that has been increasingly hard to come by in the last year. COVID-19, earthquakes, droughts, and winter storms have all had serious effects on the industry recently.
Hulu’s Android TV apps can finally stream in 1080p on new Nvidia Shield TV set-top-boxes and Sony Bravia TVs, as spotted by users on Reddit, and written up by Gizmodo, Android Central, and 9to5Google.
Users first noticed the change in the “App & Device Info” page in the Hulu app. After updating, the app lists the new max video resolution as “1920 x 1080”. It’s sort of a sneaky way to make the change. Looking at the update description on the Play Store, there’s no mention of it, so it’s possible something changed on Hulu’s server side as well.
Hulu’s App & Device Info screen that shows the new max resolution.Image: 9to5Google
Gizmodo says it was able to confirm that at least the Nvidia Shield from 2019 and Bravia TVs received the 1080p bump on March 23rd, but the change hasn’t been reflected in Hulu’s support pages, which were last updated in February. Hulu doesn’t seem to specifically list which devices stream in each resolution (outside of Live TV streaming) on its support site, but it does provide minimum bitrates for each:
Standard Definition (SD): 1.5 Mbps
High Definition (HD) 720p: 3 Mbps
High Definition (HD) 1080p: 6 Mbps
4K Ultra HD: 16 Mbps
For the newer Chromecast with Google TV, which runs a skinned version of Android TV, it’s not clear when 1080p Hulu support was added, or if it launched with it. I was able to check on my own Chromecast’s Hulu app and it does currently support 1080p. We’ve reached out to Hulu to confirm which other Android TV devices might have been affected by this update.
4K streaming is even more limited on Hulu. 4K content is primarily limited to Hulu’s original shows and movies, and according to Hulu’s likely out-of-date list, the devices that can actually stream in 4K are the 5th generation Apple TV, the Chromecast Ultra, Amazon’s Fire TV and Fire TV Stick, LG UHD TVs from 2017 onwards, Roku devices, Vizio TVs with SmartCast, and the Xbox One S and X.
It’s nice that more devices could theoretically stream in a higher resolution, especially for folks who’ve shelled out money for higher resolution displays. I do think it’s worth mentioning, however, that some of the Redditors who first found this change had no idea they’d been streaming in 720p all this time.
We use cookies on our website to give you the most relevant experience. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.